摘要
项目名称 :电影分析可视化
数据来源 :数据来源于kaggle,针对IMDb近5000部电影数据进行分析。互联网电影资料库(Internet
字段说明
id : TMDB电影标识号
title : 电影名称
cast :演员列表
director :导演
budget :预算(美元)
genres :风格列表,电影类型
popularity :在 Movie Database 上的相对页面查看次数
production_companies :制作公司
production_countries :制作国家
release_date :上映时间
revenue :收入
runtime :电影时长
spoken_languages :口语
status :状态
vote_average :平均评分
vote_count :评分次数
项目目的 :
通过对IMDb近5000部电影数据进行分析,对以下几个方面进行对比分析
电影类型分析
电影产地分析
电影导演分析
电影预算与评分与票房的关系分析
Universal Pictures公司和Paramount Picture公司之间的对比分析
原创电影与改编电影对比分析
环境解释 :基于jupyter notebook,可视化工具包:seaborn、matplotlib
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport jsonimport warningswarnings.filterwarnings('ignore' ) import osos.chdir(r'/Users/nanb/Documents/数据存放' ) %matplotlib inline plt.style.use('ggplot' )
1 2 3 4 movies = pd.read_csv('tmdb_5000_movies.csv' ,sep = ',' ) credits = pd.read_csv('tmdb_5000_credits.csv' ,sep = ',' )
数据整理 1 2 3 4 credits = credits.drop(columns = ['title' ,'movie_id' ]) movies = movies.drop(columns = ['homepage' ,'spoken_languages' ,'original_language' ,'original_title' ,'overview' ,'tagline' ,'status' ])
1 2 3 4 data = pd.concat([movies,credits],axis = 1 ) data.head()
缺失值处理 1 2 3 data.apply(lambda x:sum (x.isnull()))
budget 0
genres 0
id 0
keywords 0
popularity 0
production_companies 0
production_countries 0
release_date 1
revenue 0
runtime 2
title 0
vote_average 0
vote_count 0
cast 0
crew 0
dtype: int64
图表解析 :release_date项有一条缺失数据;runtime项有两条缺失数据
1 2 3 data[data.isnull().values==True ]
1 2 3 4 5 data.loc[2656 ,'runtime' ] = '98' data.loc[4140 ,'runtime' ] = '82' data.loc[4553 ,'release_date' ] = '2014-06-01'
数据类型转换 1 2 3 4 5 6 7 8 data['release_date' ] = pd.to_datetime(data['release_date' ],format ='%Y-%m-%d' ) data['release_year' ] = data['release_date' ].dt.year data.loc[:,'release_year' ].head()
0 2009
1 2007
2 2015
3 2012
4 2012
Name: release_year, dtype: int64
1 2 3 4 5 6 7 8 9 10 11 12 13 14 df = data.copy() json_cols = ['genres' ,'keywords' ,'production_companies' ,'production_countries' ,'cast' ,'crew' ] for i in json_cols: df[i] = df[i].apply(json.loads) def get_names (x ): return ',' .join(i['name' ] for i in x) df['genres' ] = df['genres' ].apply(get_names) df['keywords' ] = df['keywords' ].apply(get_names) df['production_companies' ] = df['production_companies' ].apply(get_names) df['production_countries' ] = df['production_countries' ].apply(get_names)
电影类型分析 1 2 3 4 5 6 7 8 9 10 11 real_genres = set () for i in df['genres' ].str .split(',' ): real_genres = real_genres.union(i) real_genres = list (real_genres) real_genres.remove(' ' ) print (real_genres)
['Foreign', 'War', 'Mystery', 'Action', 'TV Movie', 'Crime', 'Animation', 'Horror', 'Thriller', 'Romance', 'Music', 'Adventure', 'Western', 'Drama', 'Documentary', 'Science Fiction', 'History', 'Fantasy', 'Family', 'Comedy']
1 2 3 4 5 for i in real_genres: df[i] = df['genres' ].str .contains(i).apply(lambda x:1 if x else 0 )
1 2 3 4 5 6 7 part1_df = df[['release_year' ,'Mystery' , 'Science Fiction' , 'Documentary' , 'TV Movie' , 'Comedy' , 'Romance' , 'Thriller' , 'Music' , 'Western' , 'Drama' , 'Crime' , 'Horror' , 'History' , 'Fantasy' , 'War' , 'Adventure' , 'Animation' , 'Family' , 'Foreign' , 'Action' ]] year_cnt = part1_df.groupby('release_year' ).sum ()
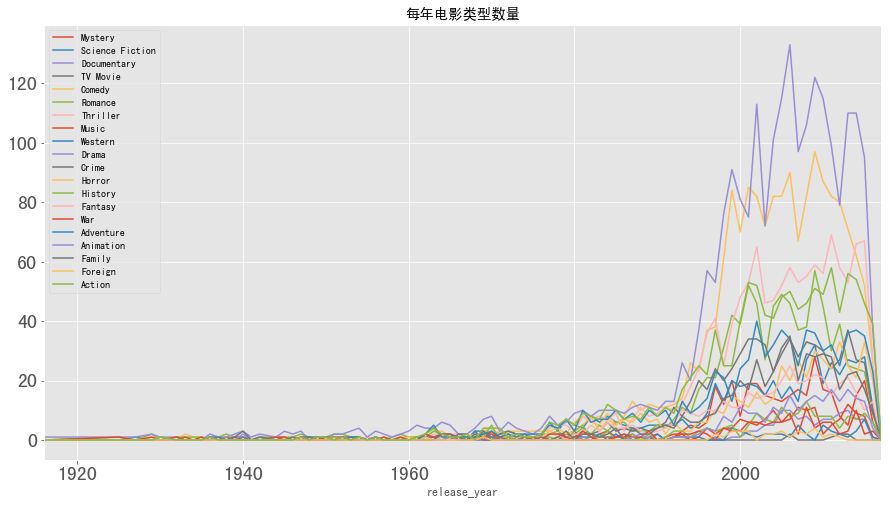
类型分析可视化 1 2 3 4 year_cnt.plot(kind = 'line' ,figsize = (15 ,8 ),fontsize = 20 ) plt.title('每年电影类型数量' )
Text(0.5, 1.0, '每年电影类型数量')
图表解析 :从图中可以看出在1916年到2017年之间,数据虽然存在波动但是总体上不同的电影类型数量都在不断扩大,其中戏剧类,喜剧类和惊悚类的增长较为迅速。这3类电影类型在市场占着主导地位。同时也可以预测这3类类型的电影人仍然会占主导地位。
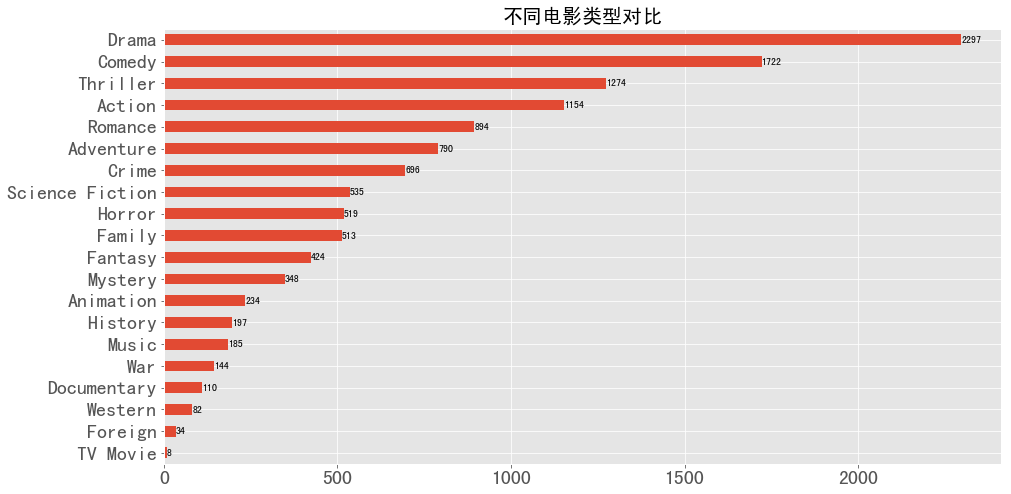
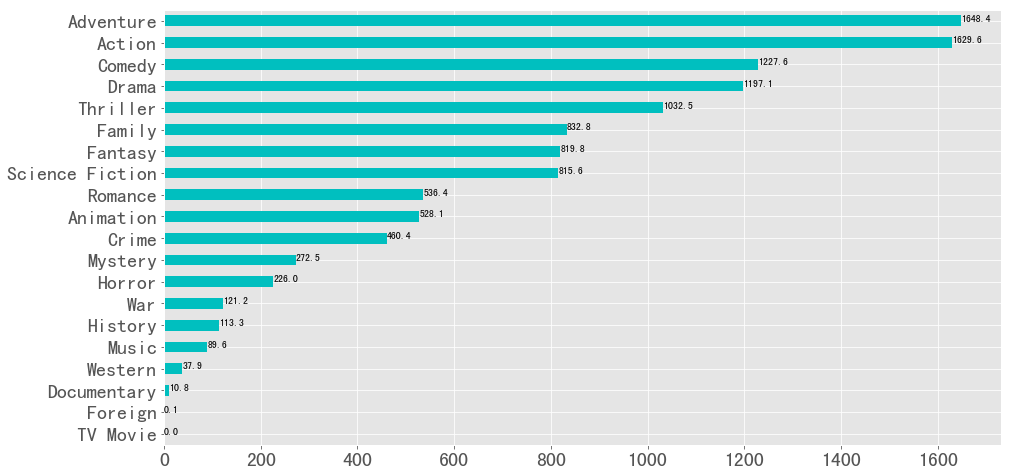
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 genre = year_cnt.sum (axis = 0 ) genre = genre.sort_values(ascending = True ) v = genre.values labels = list (genre.index) genre.plot(kind = 'barh' ,label = '' ,figsize = (15 ,8 ),fontsize = 20 ) plt.title('不同电影类型对比' ,fontsize = 20 ) for x,y in zip (v,range (len (labels))): plt.text(x,y,'{}' .format (x),ha='left' ,va='center' ) plt.show()
图表解析 :从图中可以看出戏剧类,喜剧类,惊悚类,动作类和爱情类的占比较大,数量较多,说明这5种类型在1916年到2017年受众较广。
导演分析 1 2 3 4 5 6 7 8 def director (x ): for i in x: if i['job' ] == 'Director' : return i['name' ] df['crew' ] = df['crew' ].apply(director) df.head()
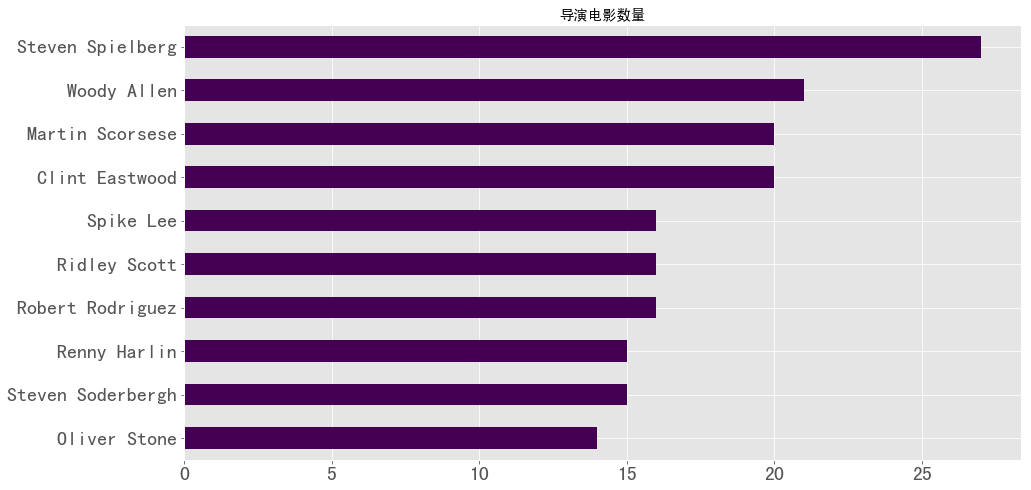
1 2 3 4 crew1 = df['crew' ].value_counts()[:10 ].sort_values(ascending = True ) crew1.plot(kind = 'barh' ,figsize = (15 ,8 ),fontsize = 20 ,colormap = 'viridis' ) plt.title('导演电影数量' ) plt.show()
图表解析 :从图中可以看出Steven Spielberg和Woody Allen是最高产的两位电影导演。
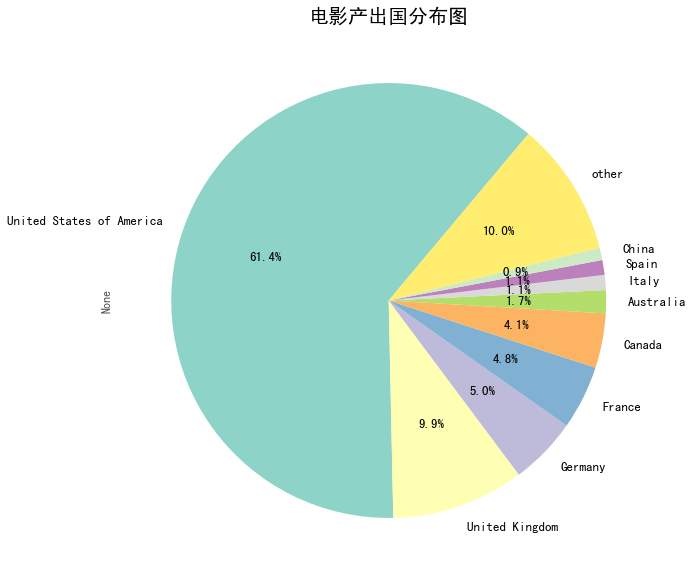
电影产地分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 countries = set () for i in df['production_countries' ].str .split(',' ): countries = countries.union(i) countries = list (countries) countries.remove(' ' ) part2_df = pd.DataFrame() for i in countries: part2_df[i] = df['production_countries' ].str .contains(i).apply(lambda x:1 if x else 0 ) part2 = part2_df.sum (axis = 0 ).sort_values(ascending = False ) part2_1 = part2[:9 ] rate = part2_1/part2.sum () other = {'other' :1 -rate.sum ()} part2_df = rate.append(pd.Series(other)) part2_df.plot(kind='pie' , startangle=50 , shadow=False , figsize=(10 ,10 ), autopct="%1.1f%%" ,fontsize = 13 ,colormap = 'Set3' ) plt.title('电影产出国分布图' ,fontsize=20 )
Text(0.5, 1.0, '电影产出国分布图')
图表解析 :从图中可以看出超过一半的电影产出国为美国,其次是英国占比约为11%,紧跟的是德国法国。美国无疑是电影业制造大亨,是世界第一的电影强国。
电影预算与评分与票房的关系分析 1 2 3 4 5 6 7 8 9 10 11 12 r = {} for i in real_genres: r[i] = df.loc[df[i] == 1 ,'revenue' ].sum (axis = 0 )/100000000 revenue = pd.Series(r).sort_values(ascending = True ) revenue.plot(kind = 'barh' ,figsize = (15 ,8 ),fontsize = 20 ,color = 'c' ) for x,y in zip (revenue.values,range (len (revenue.index))): plt.text(x,y,'{:.1f}' .format (x))
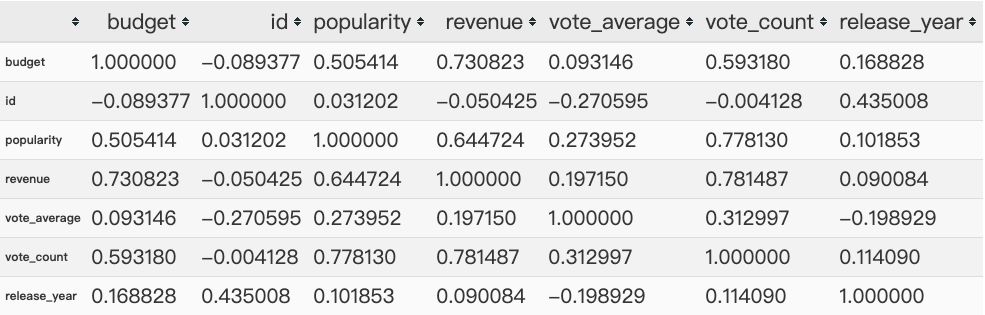
1 2 3 4 5 6 7 corr = data.corr() corr plt.figure(figsize = (12 ,8 )) sns.heatmap(corr,vmin = 0 ,vmax = 1 ,cmap = 'Set3' )
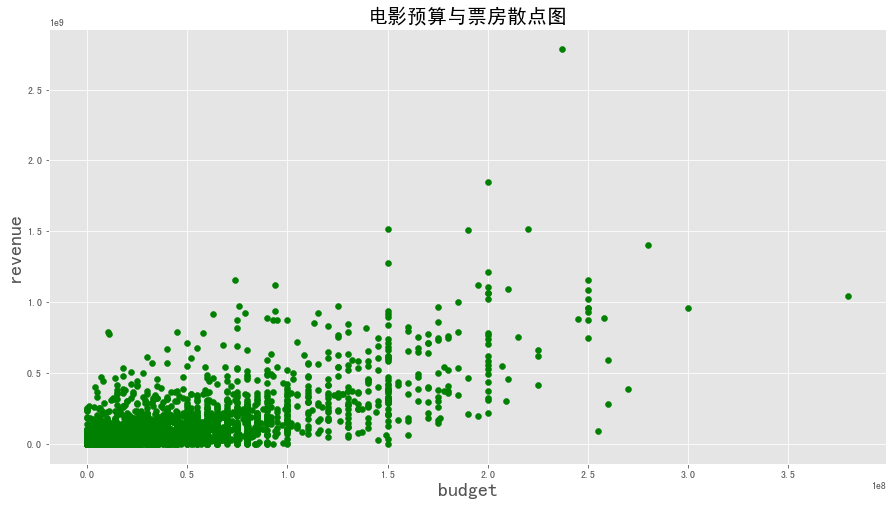
1 2 3 4 5 6 7 8 9 10 plt.figure(figsize = (15 ,8 )) x1 = data['budget' ] y1 = data['revenue' ] plt.scatter(x1,y1,color = 'g' ) plt.xlabel('budget' ,fontsize = 20 ) plt.ylabel('revenue' ,fontsize = 20 ) plt.title('电影预算与票房散点图' ,fontsize = (20 )) plt.show()
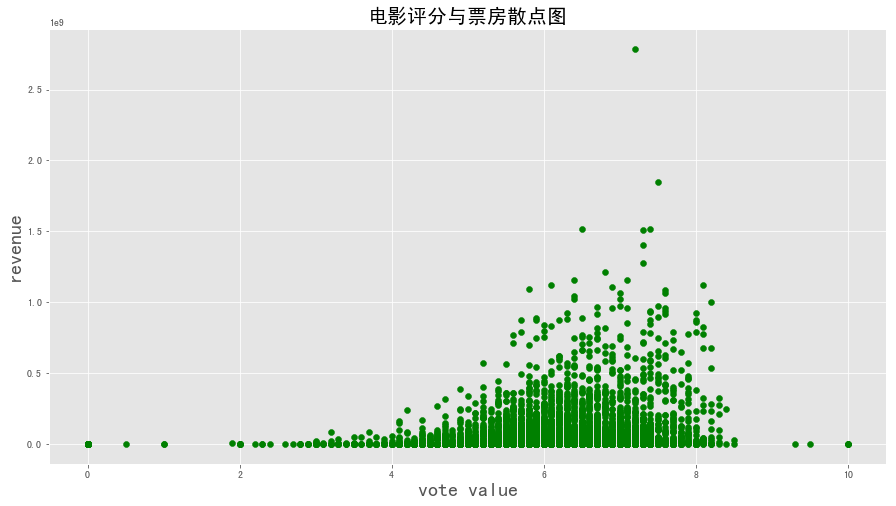
1 2 3 4 5 6 7 8 9 10 plt.figure(figsize = (15 ,8 )) x2 = data['vote_average' ] y2 = data['revenue' ] plt.scatter(x2,y2,color = 'g' ) plt.xlabel('vote value' ,fontsize = 20 ) plt.ylabel('revenue' ,fontsize = 20 ) plt.title('电影评分与票房散点图' ,fontsize = (20 )) plt.show()
图表解析 :从图中以及计算出的相关系数可以得知电影预算和票房存在正线性相关关系,电影评分与票房也存在着正线性相关关系,但前者的相关性较大,有0.73,后者较小只有0.2。
可以得知一般预算较大的电影票房收入也会不错,但是电影评分高的电影票房收入不见得就多。例如一些小众电影评分会较高但是由于电影排档日期较短的原因票房表现也较为一般。
原创电影与改编电影分析 1 2 3 4 part3_df = data.loc[:,['release_year' ,'keywords' ]] part3_df['adaptation' ] = part3_df['keywords' ].str .contains('based on novel' ).apply(lambda x:1 if x else 0 ) part3_df['original' ] = part3_df['keywords' ].str .contains('based on novel' ).apply(lambda x:0 if x else 1 ) part3_df.head()
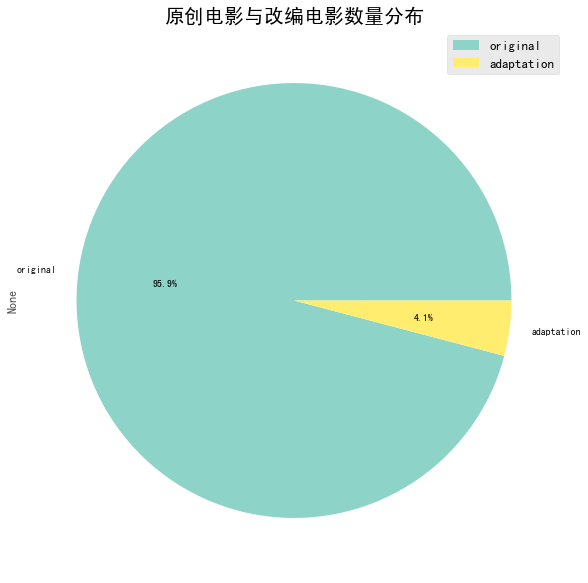
1 2 3 4 5 6 org_ada_all = org_ada_df.sum (axis = 0 ) org_ada_rate = org_ada_all/sum (org_ada_all) org_ada_all.plot(kind = 'pie' ,figsize=(10 ,10 ),shadow = False , autopct = '%1.1f%%' ,legend = True ,colormap='Set3' ) plt.legend(fontsize = 13 ) plt.title('原创电影与改编电影数量分布' ,fontsize = 20 )
Text(0.5, 1.0, '原创电影与改编电影数量分布')
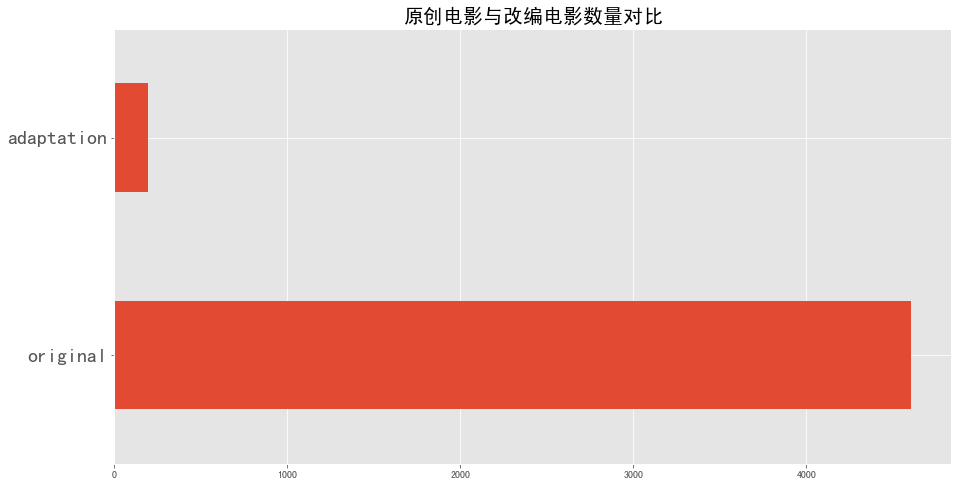
1 2 3 org_ada_all.plot(kind = 'barh' ,figsize = (15 ,8 )) plt.yticks(fontsize = 20 ) plt.title('原创电影与改编电影数量对比' ,fontsize = 20 )
Text(0.5, 1.0, '原创电影与改编电影数量对比')
图表解析 :从图中可以看出占96%的电影为原创电影,原创电影的数量远远大于改编电影,说明原创电影比较受市场的追捧。
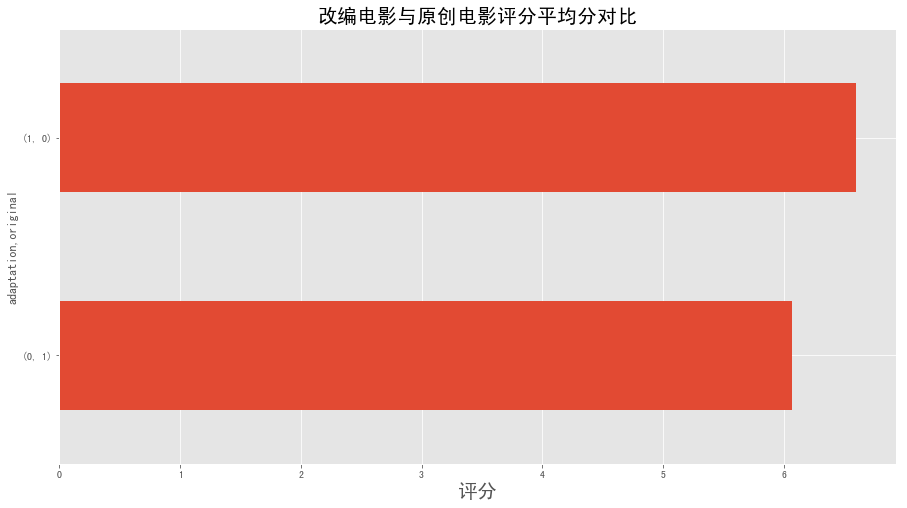
1 2 3 4 5 6 7 8 part3_df['vote_value' ] = data['vote_average' ] avg_vote = part3_df.groupby(['adaptation' ,'original' ])['vote_value' ].mean() avg_vote avg_vote.plot(kind='barh' ,label='' ,figsize=(12 ,6 )) plt.xlabel('评分' ,fontsize = 20 ) plt.title('改编电影与原创电影评分平均分对比' ,fontsize=20 ) plt.show()
图表解析 :改编电影的平均分为6.60,原创电影的平均分为6.07,两者相差不大,改编电影略高,说明改编电影的质量较高,口碑较好。
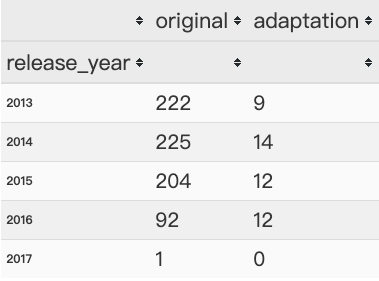
1 2 org_ada_df = part3_df.groupby('release_year' )['original' ,'adaptation' ].sum (axis = 0 ) org_ada_df.tail()
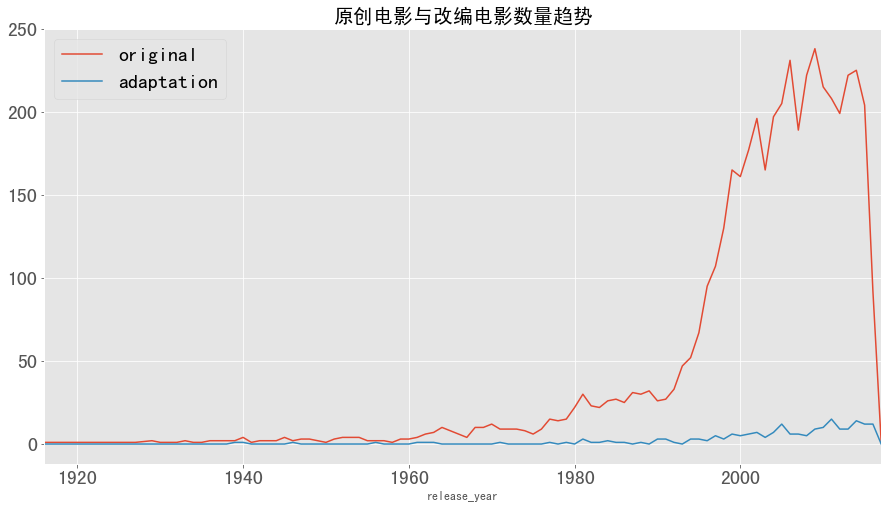
1 2 3 4 5 org_ada_df.plot(figsize = (15 ,8 )) plt.legend(fontsize = 20 ) plt.yticks(fontsize = 20 ) plt.xticks(fontsize = 20 ) plt.title('原创电影与改编电影数量趋势' ,fontsize = 20 )
Text(0.5, 1.0, '原创电影与改编电影数量趋势')
图表解析 :由图可看出,原创电影一直在不断上涨,且在1990年至2000年后出现了指数型增长,而改编电影的数量一直变化不大
公司对比分析
Universal Pictures 公司和Paramount Picture 公司之间的对比分析
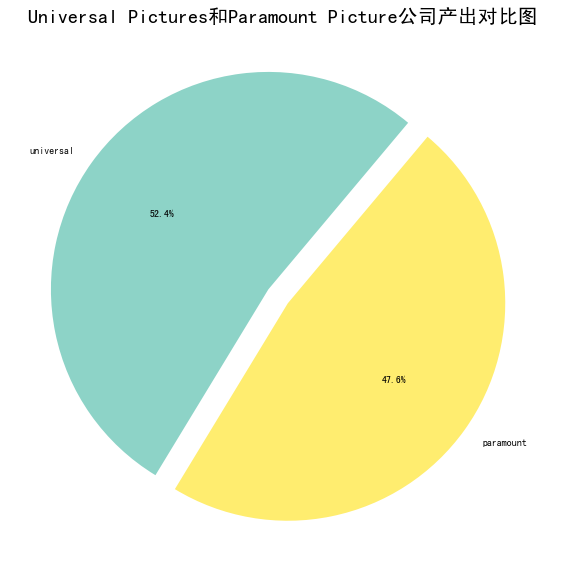
产出对比 1 2 3 4 5 6 7 8 9 10 company_df = pd.DataFrame() company_df['universal' ]=data['production_companies' ].str .contains('Universal Pictures' ).map (lambda x:1 if x else 0 ) company_df['paramount' ]=data['production_companies' ].str .contains('Paramount Pictures' ).map (lambda x:1 if x else 0 ) part5_df = company_df.sum (axis = 0 ) company_rate = part5_df/part5_df.sum () explode =(company_rate>0.5 )/20 +0.03 part5_df.plot(kind='pie' , label='' , startangle=50 , shadow=False , figsize=(10 ,10 ), autopct="%1.1f%%" ,colormap = 'Set3' , explode=explode) plt.title('Universal Pictures和Paramount Picture公司产出对比图' ,fontsize=20 )
Text(0.5, 1.0, 'Universal Pictures和Paramount Picture公司产出对比图')
图表解析 :可以看出,universal picture比paramout picture 产出占比略大
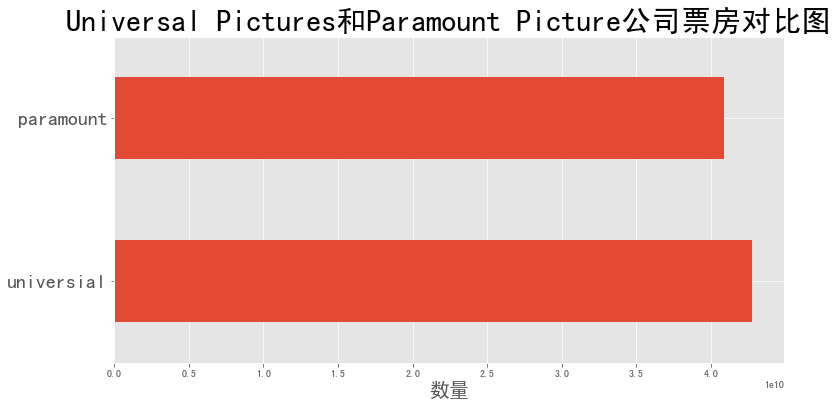
票房对比 1 2 3 4 5 6 7 8 9 company_revenue = pd.DataFrame() company_revenue['universial' ] = company_df['universal' ] * data['revenue' ] company_revenue['paramount' ] = company_df['paramount' ] * data['revenue' ] part6_df = company_revenue.sum () part6_df.plot(kind='barh' ,label='' ,figsize=(12 ,6 )) plt.xlabel('数量' ,fontsize=20 ) plt.yticks(fontsize = 20 ) plt.title('Universal Pictures和Paramount Picture公司票房对比图' ,fontsize=30 ) plt.show()
图表解析 :可以看出,虽然universal picture比paramout picture 票房略高,但相差不大。
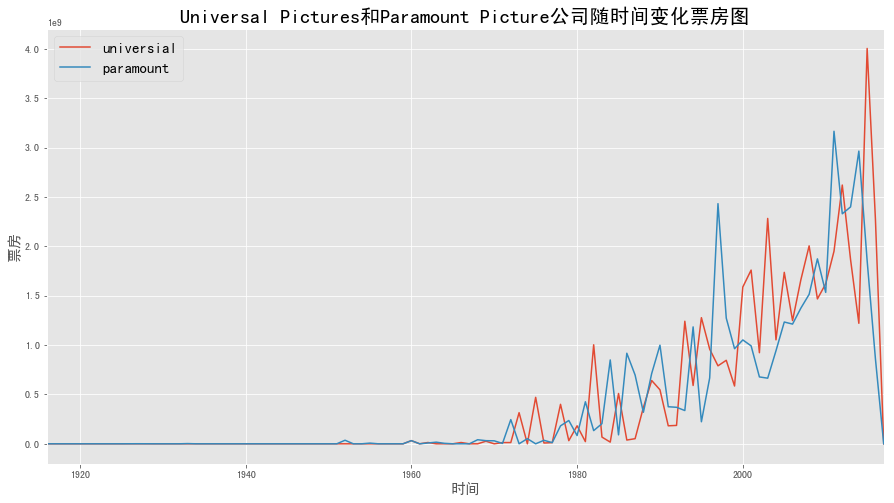
1 2 3 4 5 6 7 8 9 10 11 company_revenue.index = data['release_year' ] company_revenue.sort_index() part7_df = company_revenue.groupby('release_year' ).sum () part7_df.plot(figsize = (15 ,8 )) plt.xlabel('时间' ,fontsize=15 ) plt.ylabel('票房' ,fontsize=15 ) plt.legend(fontsize = 15 ) plt.title('Universal Pictures和Paramount Picture公司随时间变化票房图' ,fontsize=20 ) plt.grid(True )
图表解析 :可以看出1960年后票房开始增长,2000年派拉蒙的票房成绩大部分时间都比环球要好,2000年环球的票房成绩大部分比派拉蒙要好,且环球的最高票房要高于派拉蒙。总体来说两家电影公司的票房相差的不是很大,都有波动。
总结
戏剧类与喜剧类所占市场份额最大,最受欢迎。
Steven Spielberg和Woody Allen是最高产的两位电影导演。
总体来说派拉蒙与环球电影公司在电影市场上平分秋色。
电影市场上的主体是原创电影。改编电影的口碑略好于原创电影。
以上是对kaggle上的IMDb电影数据进行的一部分对比分析与可视化。数据本身还有待分析与挖掘的角度,有任何错误的地方,恳请指正,感谢阅读~