摘要
项目名称 :泰坦尼克号生存分析
数据来源 :Kaggle数据集 → 共有1309名乘客数据,其中891是已知存活情况(train.csv),剩下418则是需要进行分析预测的(test.csv)
字段意义 :
PassengerId : 乘客编号
Survived:是否存活(1:存活;0:死亡)
Pclass:客舱等级
Name:乘客姓名
Sex:乘客性别
Age:乘客年龄
SibSp:同乘的兄弟姐妹/配偶人数
Parch:同乘的父母/小孩人数
Ticket:船票编号
Fare:船票价格
Cabin:客舱号
Embarked:登船港口
项目目的 :通过已知的获救数据,预测乘客的生存情况
环境解释 :基于jupyter notebook,可视化工具包:seaborn、matplotlib
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import pandas as pdimport numpy as npimport matplotlib.pyplot as plt%matplotlib inline import matplotlibmatplotlib.style.use('ggplot' ) import seaborn as snssns.set (context='notebook' ,style='white' ,palette='muted' ) import warningswarnings.filterwarnings('ignore' ) import osos.chdir(r'/Users/nanb/Documents/数据存放' )
1 2 3 4 train = pd.read_csv('train.csv' ) test = pd.read_csv('test.csv' )
存活比例分析
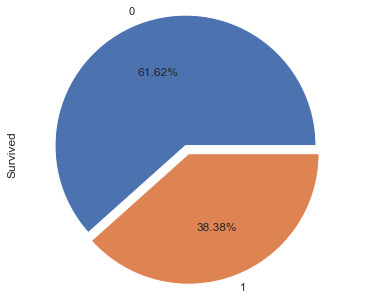
整体来看,存活比例是怎样
1 2 3 4 5 6 7 8 sns.set () sns.set_style('ticks' ) plt.axis('equal' ) train['Survived' ].value_counts().plot.pie(radius=1.5 , explode=[0.1 ,0 ], autopct = '%1.2f%%' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a25a0cef0>
图表解析 :存活比例仅为38.38%
年龄分析
结合年龄数据,分析幸存下来的人有什么特点
问题2:结合性别和年龄,分析幸存下来的人有什么特点
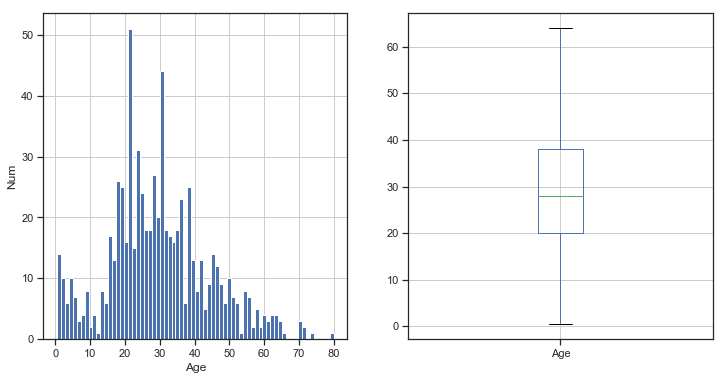
1、年龄数据的分布情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 sum (train['Age' ].isnull())train_age = train[train['Age' ].notnull()] plt.figure(figsize = (12 ,6 )) plt.subplot(121 ) train_age['Age' ].hist(bins = 70 ) plt.xlabel('Age' ) plt.ylabel('Num' ) plt.subplot(122 ) train_age.boxplot(column = 'Age' ,showfliers = False ) train_age['Age' ].describe()
count 714.000000
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000
50% 28.000000
75% 38.000000
max 80.000000
Name: Age, dtype: float64
图表解析 :
总体年龄分布:去掉缺失值后样本值共:714条,平均年龄为:29.70,标准差为:15,最小年龄为:0.42,最大年龄为:80
性别分析
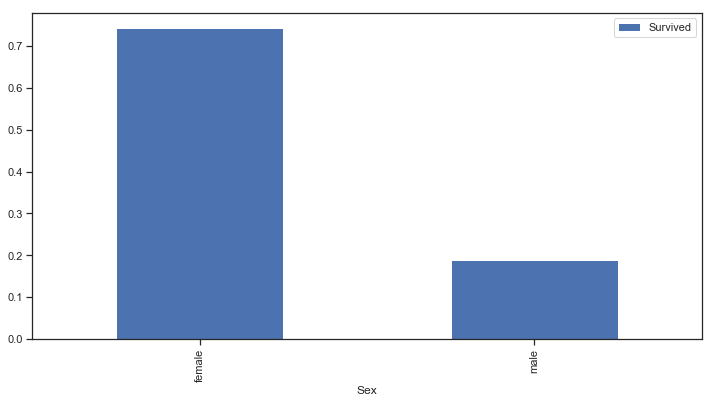
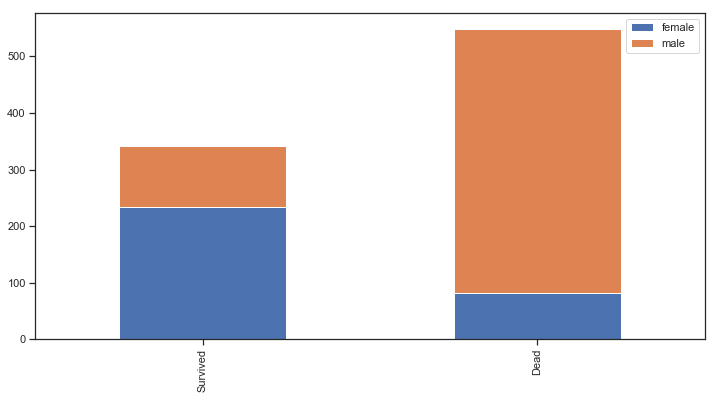
分析男性和女性的存活情况
1 2 3 4 5 6 7 8 9 10 11 12 13 train[['Sex' ,'Survived' ]].groupby(['Sex' ]).mean().plot.bar(figsize = (12 ,6 )) survived_sex = train[train['Survived' ] == 1 ]['Sex' ].value_counts() dead_sex = train[train['Survived' ] == 0 ]['Sex' ].value_counts() df = pd.DataFrame([survived_sex,dead_sex]) df.index = ['Survived' ,'Dead' ] df.plot(kind = 'bar' ,stacked = True ,figsize = (12 ,6 ))
<matplotlib.axes._subplots.AxesSubplot at 0x1a2620ee10>
图表解析 :不难看出,无论是总体上,还是在幸存者中的女性占比都远大于男性。
年龄分析 - 老人与小孩
结合年龄数据,分析存活者中老人与小孩的占比
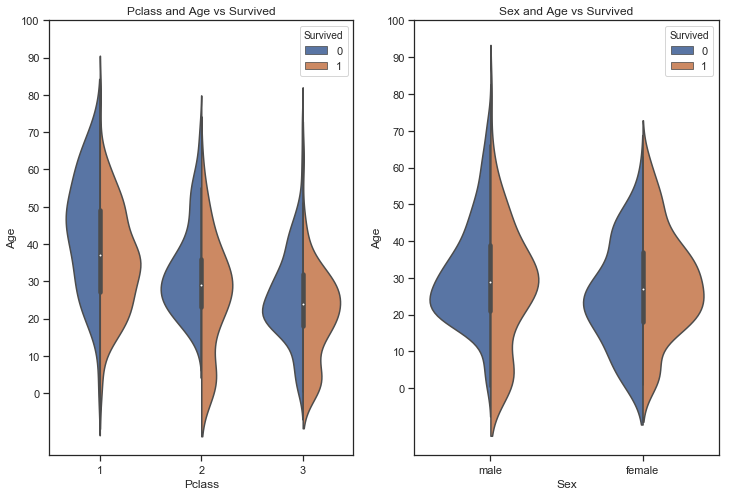
1 2 3 4 5 6 7 8 9 10 11 12 13 fig,ax = plt.subplots(1 ,2 ,figsize = (12 ,8 )) sns.violinplot('Pclass' ,'Age' ,hue = 'Survived' ,data = train, split = True ,ax = ax[0 ]) ax[0 ].set_title('Pclass and Age vs Survived' ) ax[0 ].set_yticks(range (0 ,110 ,10 )) sns.violinplot('Sex' ,'Age' ,hue = 'Survived' ,data = train, split = True ,ax = ax[1 ]) ax[1 ].set_title('Sex and Age vs Survived' ) ax[1 ].set_yticks(range (0 ,110 ,10 ))
[<matplotlib.axis.YTick at 0x1a2617af60>,
<matplotlib.axis.YTick at 0x1a25fb6d68>,
<matplotlib.axis.YTick at 0x1a252fcc88>,
<matplotlib.axis.YTick at 0x1a25b9c6d8>,
<matplotlib.axis.YTick at 0x1a25b9cbe0>,
<matplotlib.axis.YTick at 0x1a25b9c160>,
<matplotlib.axis.YTick at 0x1a25bc65c0>,
<matplotlib.axis.YTick at 0x1a25bc6c18>,
<matplotlib.axis.YTick at 0x1a25fd8e10>,
<matplotlib.axis.YTick at 0x1a25bc6668>,
<matplotlib.axis.YTick at 0x1a25b9c588>]
图表解析 :
从小提琴图中可以看出:
1、在按照不同船舱等级划分时:船舱等级越高,存活者的年龄越大;而在船舱等级1中存活年龄集中在20-40岁,在船舱等级2和船舱等级3中有较多的低龄乘客存活
2、在按照性别划分时:男性和女性存活者的年龄多数分布在20-40岁,且均有较多的低龄乘客存活,其中女性存活远多余男性
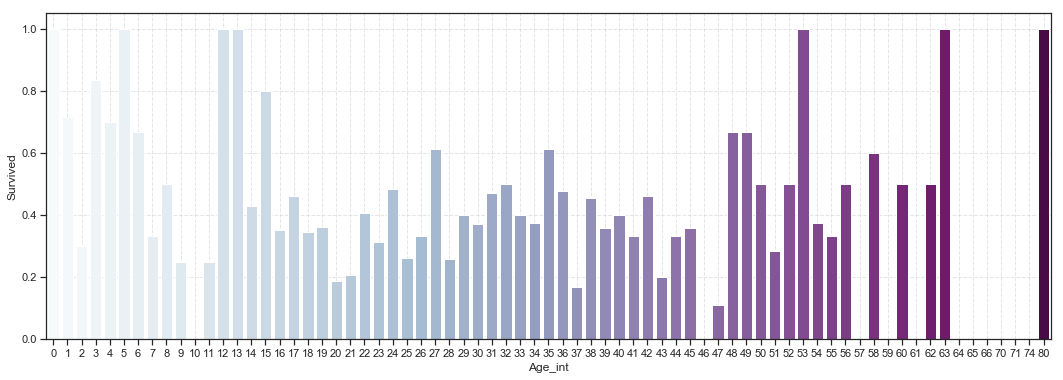
1 2 3 4 5 6 7 8 plt.figure(figsize = (18 ,6 )) train_age['Age_int' ] = train_age['Age' ].astype(int ) average_age = train_age[['Age_int' ,'Survived' ]].groupby(['Age_int' ],as_index = False ).mean() sns.barplot(x = 'Age_int' ,y = 'Survived' ,data = average_age, palette = 'BuPu' ) plt.grid(linestyle = '--' ,alpha = 0.5 )
图表解析 :灾难中,老人和小孩的存活几率较高
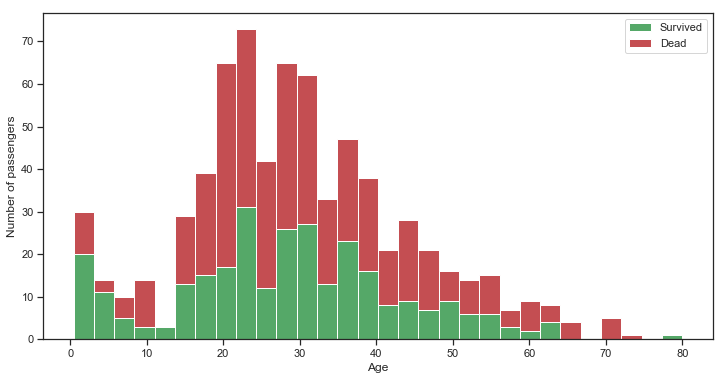
1 2 3 4 5 6 7 8 9 plt.figure(figsize = (12 ,6 )) plt.hist([train[train['Survived' ] == 1 ]['Age' ],train[train['Survived' ] == 0 ]['Age' ]], stacked = True , color = ['g' ,'r' ], bins = 30 , label = ['Survived' ,'Dead' ]) plt.xlabel('Age' ) plt.ylabel('Number of passengers' ) plt.legend()
<matplotlib.legend.Legend at 0x1a26a845f8>
图表解析 :大概在十二岁以下的小孩与近80岁的老人存活率相对高很多
探索亲人的人数与存活
结合SibSp、Parch字段,探索亲人的人数与存活的关系
1、有无兄弟姐妹/父母子女与是否存活之间的关系
2、亲戚人数和存活与否之间的关系
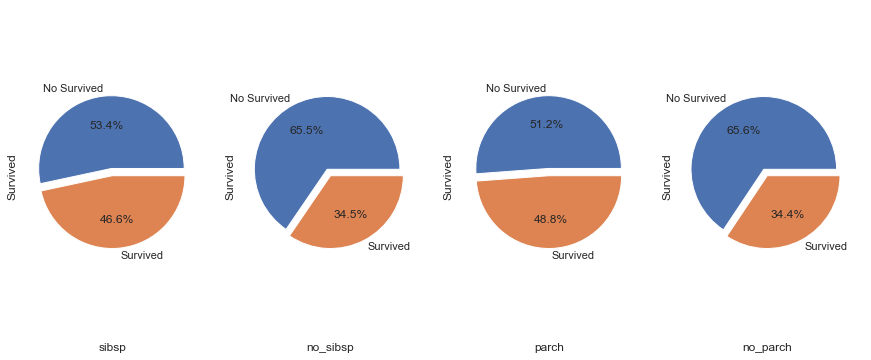
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 sibsp_df = train[train['SibSp' ] != 0 ] no_sibsp_df = train[train['SibSp' ] == 0 ] parch_df = train[train['Parch' ] != 0 ] no_parch_df = train[train['Parch' ] == 0 ] plt.figure(figsize = (15 ,6 )) plt.subplot(141 ) plt.axis('equal' ) sibsp_df['Survived' ].value_counts().plot.pie(labels = ['No Survived' ,'Survived' ], autopct = '%1.1f%%' , explode=[0.1 ,0 ]) plt.xlabel('sibsp' ) plt.subplot(142 ) plt.axis('equal' ) no_sibsp_df['Survived' ].value_counts().plot.pie(labels = ['No Survived' ,'Survived' ], autopct = '%1.1f%%' , explode=[0.1 ,0 ]) plt.xlabel('no_sibsp' ) plt.subplot(143 ) plt.axis('equal' ) parch_df['Survived' ].value_counts().plot.pie(labels = ['No Survived' ,'Survived' ], autopct = '%1.1f%%' , explode=[0.1 ,0 ]) plt.xlabel('parch' ) plt.subplot(144 ) plt.axis('equal' ) no_parch_df['Survived' ].value_counts().plot.pie(labels = ['No Survived' ,'Survived' ], autopct = '%1.1f%%' , explode=[0.1 ,0 ]) plt.xlabel('no_parch' )
图表解析 :相比较而言,有兄弟姐妹的乘客存活率会比无兄弟姐妹高;而有父母子女的乘客存活率也会比无父母子女的乘客存活率高
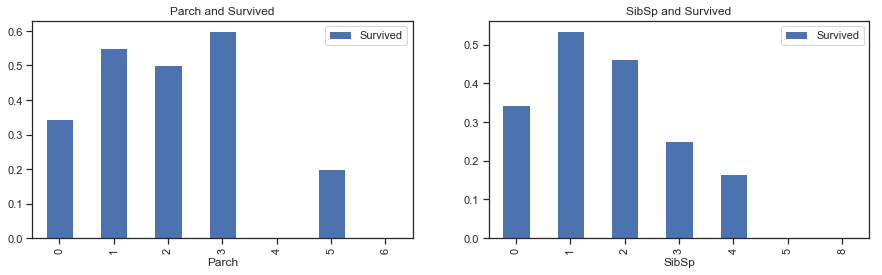
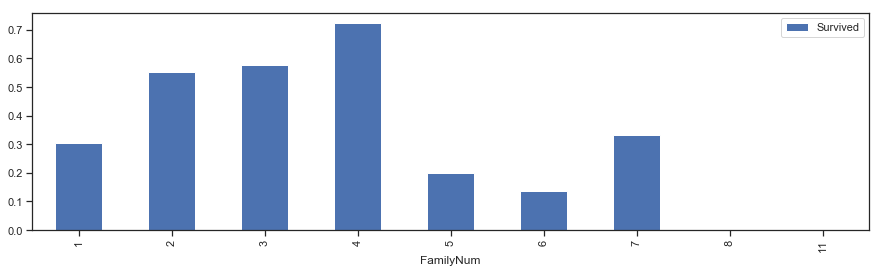
1 2 3 4 5 6 7 8 9 10 fig,ax = plt.subplots(1 ,2 ,figsize = (15 ,4 )) train[['Parch' ,'Survived' ]].groupby(['Parch' ]).mean().plot.bar(ax = ax[0 ]) ax[0 ].set_title('Parch and Survived' ) train[['SibSp' ,'Survived' ]].groupby(['SibSp' ]).mean().plot.bar(ax = ax[1 ]) ax[1 ].set_title('SibSp and Survived' ) train['FamilyNum' ] = train['Parch' ] + train['SibSp' ] + 1 train[['FamilyNum' ,'Survived' ]].groupby(['FamilyNum' ]).mean().plot.bar(figsize = (15 ,4 ))
<matplotlib.axes._subplots.AxesSubplot at 0x1a27223908>
图表解析 :如果乘客为独自一人,其存活率并不高;而如果亲友过多,其存活率会更低
票价分析
结合Fare字段,探究票价与是否存活有无关系
1、研究票价分布与是否存活之间的联系
2、研究生还者与未生还者的票价情况
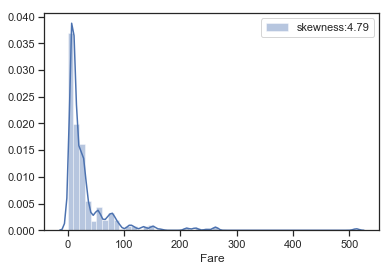
1 2 3 4 fareplot = sns.distplot(train['Fare' ],label = 'skewness:%.2f' % (train['Fare' ].skew())) fareplot.legend()
<matplotlib.legend.Legend at 0x1a272af7f0>
图表解析 :可以看出,票价在0-40区间数量最多
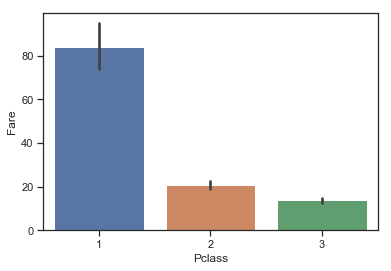
1 2 3 sns.barplot(data = train,x = 'Pclass' ,y = 'Fare' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a276fc438>
图表解析 :很明显:船舱等级最高为1(票价也最高),依次后排
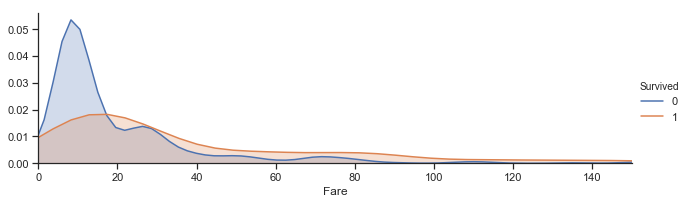
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 fare_survived = sns.FacetGrid(train,hue = 'Survived' ,aspect = 3 ) fare_survived.map (sns.kdeplot,'Fare' ,shade = True ) fare_survived.set (xlim = (0 ,150 )) fare_survived.add_legend()
<seaborn.axisgrid.FacetGrid at 0x1a27758a90>
图表解析 :当票价低于18左右时,该部分乘客的生存率较低;而随着票价越高生存率一般较高
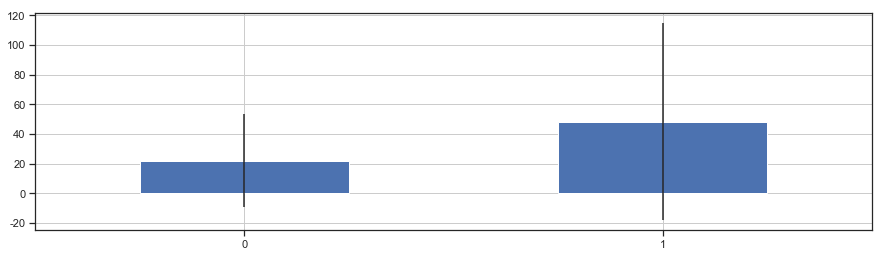
1 2 3 4 5 6 7 8 9 10 11 12 fare_not_survived = train['Fare' ][train['Survived' ] == 0 ] fare_survived = train['Fare' ][train['Survived' ] == 1 ] avg_fare = pd.DataFrame([fare_not_survived.mean(),fare_survived.mean()]) std_fare = pd.DataFrame([fare_not_survived.std(),fare_survived.std()]) avg_fare.plot(yerr = std_fare,kind = 'bar' ,legend = False , figsize = (15 ,4 ),grid = True ) plt.xticks(rotation = 360 )
(array([0, 1]), <a list of 2 Text xticklabel objects>)
图表解析 :生还者的平均票价要大于未生还者的平均票价
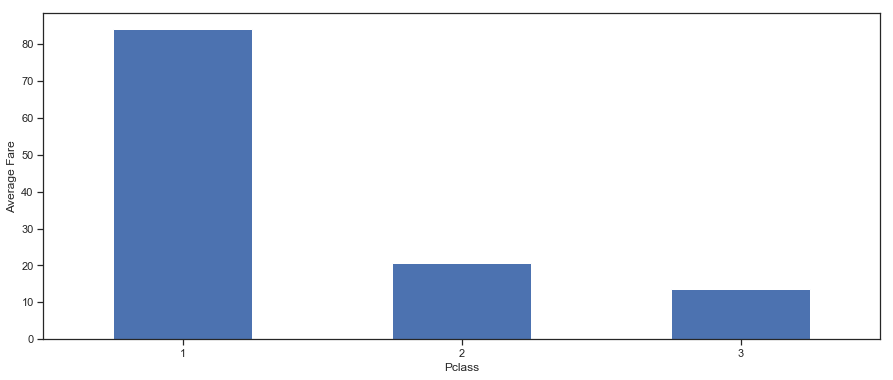
1 2 3 4 5 6 7 8 ax = plt.subplot() ax.set_ylabel('Average Fare' ) train.groupby('Pclass' ).mean()['Fare' ].plot(kind = 'bar' , figsize = (15 ,6 ), ax = ax) plt.xticks(rotation = 360 )
(array([0, 1, 2]), <a list of 3 Text xticklabel objects>)
图表解析 :船舱等级高,船票均价自然高
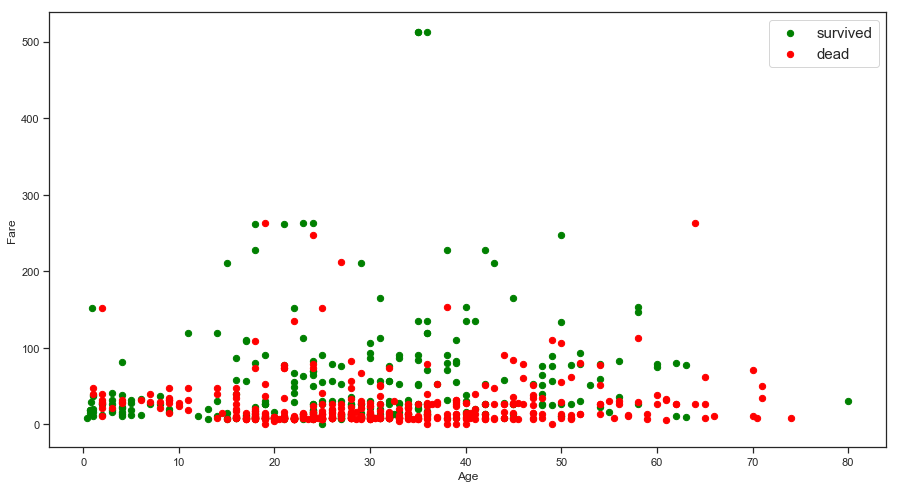
1 2 3 4 5 6 7 8 9 10 plt.figure(figsize = (15 ,8 )) ax = plt.subplot() ax.scatter(train[train['Survived' ] == 1 ]['Age' ],train[train['Survived' ] == 1 ]['Fare' ],c = 'green' ,s = 40 ) ax.scatter(train[train['Survived' ] == 0 ]['Age' ],train[train['Survived' ] == 0 ]['Fare' ],c = 'red' ,s = 40 ) ax.set_xlabel('Age' ) ax.set_ylabel('Fare' ) ax.legend(('survived' ,'dead' ),scatterpoints = 1 , loc = 'upper right' ,fontsize = 15 )
<matplotlib.legend.Legend at 0x1a27f58e10>
图表解析 :基本与上面的分析相吻合,票价高的存活率高,且老人和小孩的生存率也相对而言较高
登船港口分析
结合Embarked字段,分析登船港口与是否存活之间的关系
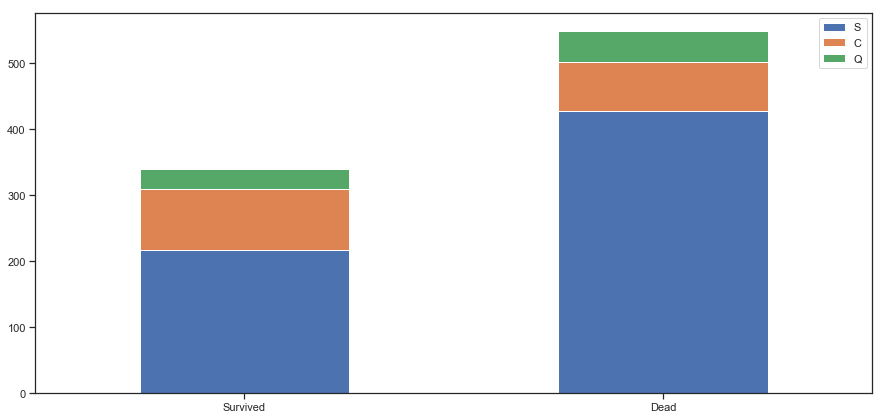
1 2 3 4 5 6 7 8 9 survived_embark = train[train['Survived' ] == 1 ]['Embarked' ].value_counts() dead_embark = train[train['Survived' ] == 0 ]['Embarked' ].value_counts() df_embark = pd.DataFrame([survived_embark,dead_embark], index = ['Survived' ,'Dead' ]) df_embark.plot(kind = 'bar' ,stacked = True ,figsize = (15 ,7 )) plt.xticks(rotation = 360 )
(array([0, 1]), <a list of 2 Text xticklabel objects>)
图表解析 :S港口登船的乘客基数最大,而在C港口登船的乘客的存活率相对而言高于另外两个港口
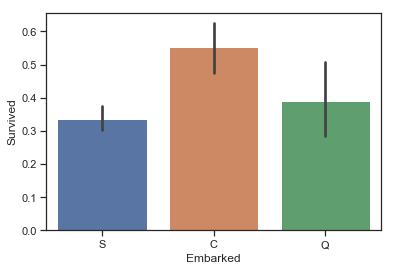
1 2 3 4 5 6 sns.barplot(data = train,x = 'Embarked' ,y = 'Survived' ) print ('Embarked为S的乘客,其生存率为%.2f' % train['Survived' ][train['Embarked' ] == 'S' ].value_counts(normalize = True )[1 ])print ('Embarked为C的乘客,其生存率为%.2f' % train['Survived' ][train['Embarked' ] == 'C' ].value_counts(normalize = True )[1 ])print ('Embarked为Q的乘客,其生存率为%.2f' % train['Survived' ][train['Embarked' ] == 'Q' ].value_counts(normalize = True )[1 ])
Embarked为S的乘客,其生存率为0.34
Embarked为C的乘客,其生存率为0.55
Embarked为Q的乘客,其生存率为0.39
图表解析 :登船港口为C的乘客存活率较高,探究是否与船舱等级比例有关联
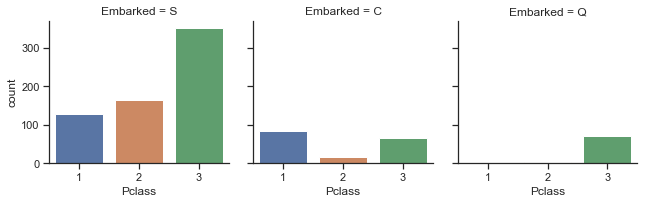
1 2 3 4 sns.factorplot('Pclass' ,col = 'Embarked' ,data = train, kind = 'count' ,size = 3 )
<seaborn.axisgrid.FacetGrid at 0x1a2821d908>
图表解析 :登船港口为C的乘客其头等舱所占的比例相对较高
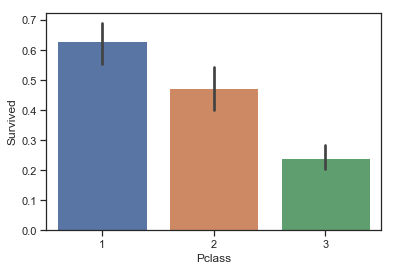
1 2 3 sns.barplot(data = train,x = 'Pclass' ,y = 'Survived' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a28789438>
图表解析 :登船港口为C的乘客其存活率较高的原因是为其是头等舱乘客占比较大,而头等舱乘客存活率也比较高
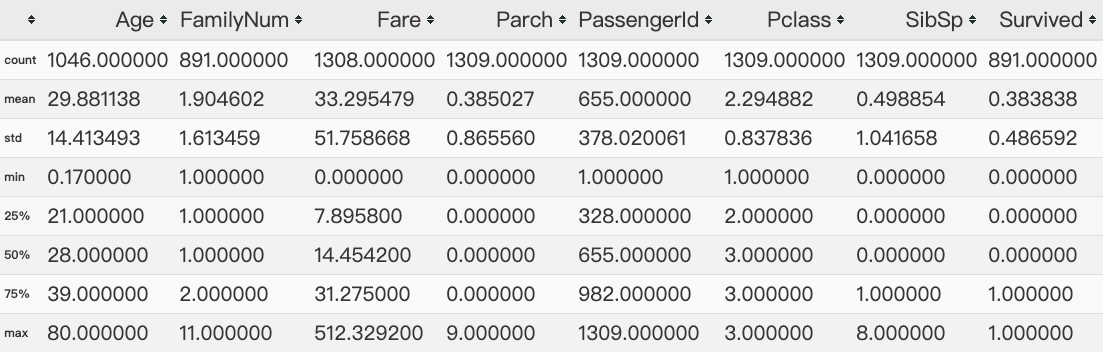
数据处理 1 2 3 4 data = train.append(test,ignore_index = True ) data.describe()
1 2 3 data.apply(lambda x:sum (x.isnull()))
Age 263
Cabin 1014
Embarked 2
FamilyNum 418
Fare 1
Name 0
Parch 0
PassengerId 0
Pclass 0
Sex 0
SibSp 0
Survived 418
Ticket 0
dtype: int64
缺失值填充
Cabin、Age、Embarked、Fare有缺失值
1 2 3 4 data['Cabin' ] = data['Cabin' ].fillna('U' )
U 1014
C23 C25 C27 6
G6 5
B57 B59 B63 B66 5
...
B73 1
A10 1
A16 1
Name: Cabin, Length: 187, dtype: int64
1 2 3 4 5 data['Embarked' ] = data['Embarked' ].fillna('S' )
1 2 3 4 5 6 7 data['Fare' ] = data['Fare' ].fillna(data[(data['Pclass' ] == 3 )&(data['Embarked' ] == 'C' )&(data['Cabin' ] == 'U' )]['Fare' ].mean())
特征1 - Title
乘客姓名中包含头衔信息,而不同的头衔也在一定程度上反映了乘客的身份,不同身份的乘客其存活率可能有差异,因此可以根据姓名信息提取Title特征,进行分析
1 2 data['Title' ] = data['Name' ].map (lambda x:x.split(',' )[1 ].split('.' )[0 ].strip()) data['Title' ].value_counts()
Mr 757
Miss 260
Mrs 197
Master 61
Rev 8
Dr 8
Col 4
Mlle 2
Major 2
Ms 2
the Countess 1
Dona 1
Mme 1
Don 1
Capt 1
Lady 1
Sir 1
Jonkheer 1
Name: Title, dtype: int64
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 TitleDict = {} TitleDict['Mr' ]='Mr' TitleDict['Mlle' ]='Miss' TitleDict['Miss' ]='Miss' TitleDict['Master' ]='Master' TitleDict['Jonkheer' ]='Master' TitleDict['Mme' ]='Mrs' TitleDict['Ms' ]='Mrs' TitleDict['Mrs' ]='Mrs' TitleDict['Don' ]='Royalty' TitleDict['Sir' ]='Royalty' TitleDict['the Countess' ]='Royalty' TitleDict['Dona' ]='Royalty' TitleDict['Lady' ]='Royalty' TitleDict['Capt' ]='Officer' TitleDict['Col' ]='Officer' TitleDict['Major' ]='Officer' TitleDict['Dr' ]='Officer' TitleDict['Rev' ]='Officer' data['Title' ] = data['Title' ].map (TitleDict) data['Title' ].value_counts()
Mr 757
Miss 262
Mrs 200
Master 62
Officer 23
Royalty 5
Name: Title, dtype: int64
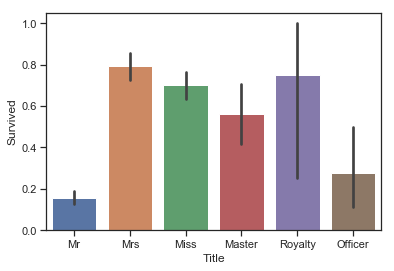
1 2 3 sns.barplot(data = data,x = 'Title' ,y = 'Survived' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a2894ce10>
图表解析 :头衔为’Mr’和’Officer’的乘客,存活率明显低于其他几类
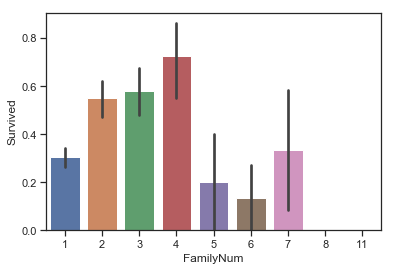
1 2 3 4 data['FamilyNum' ] = data['SibSp' ] + data['Parch' ] + 1 sns.barplot(data = data,x = 'FamilyNum' ,y = 'Survived' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a28a4b240>
特征2 - FamilySize
根据家庭人数生成FamilySize(家庭规模)类别,有小、中、大三类
1 2 3 4 5 6 7 8 9 10 11 def familysize (FamilyNum ): if FamilyNum == 1 : return 0 elif (FamilyNum >= 2 )&(FamilyNum <= 4 ): return 1 else : return 2 data['FamilySize' ] = data['FamilyNum' ].map (familysize) data['FamilySize' ].value_counts()
0 790
1 437
2 82
Name: FamilySize, dtype: int64
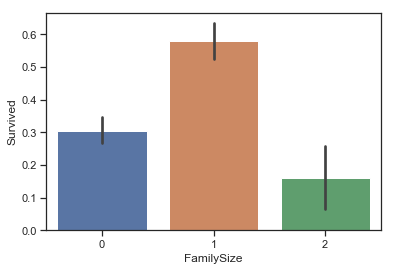
1 sns.barplot(data = data,x = 'FamilySize' ,y = 'Survived' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a28b57940>
图表解析 :当家庭规模适中时,乘客的生存率更高。
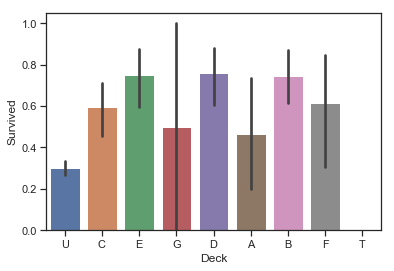
特征3 - Deck
Cabin字段的首字母代表客舱的类型,也反映不同乘客群体的特点,可能也与乘客的生存率相关。
1 2 3 4 data['Deck' ] = data['Cabin' ].map (lambda x:x[0 ]) sns.barplot(data = data,x = 'Deck' ,y = 'Survived' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a28afe748>
图表解析 :明显看出,客舱类型为B、D、E的乘客的存活率较高;客舱类型为U、T时,存活率低
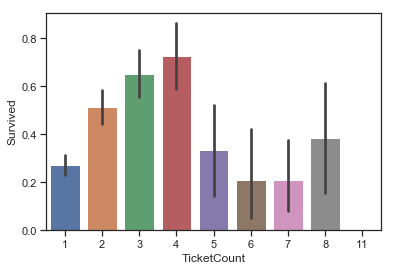
特征4 - TicketCount
同一票号的乘客数量有所不同,可能与乘客的生存率也有关系,生成新特征TicketCount
1 2 3 4 5 6 7 8 9 10 11 12 13 14 data['Ticket' ].value_counts() TicketCountdict = {} TicketCountdict = data['Ticket' ].value_counts() TicketCountdict.head() data['TicketCount' ] = data['Ticket' ].map (TicketCountdict) sns.barplot(data = data,x = 'TicketCount' ,y = 'Survived' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a28cf7940>
图表解析 :当TicketCount大小适中时,乘客的存活率较高
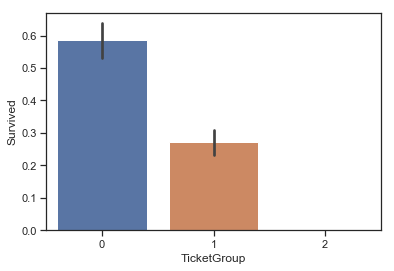
特征5 - TicketGroup 1 2 3 4 5 6 7 8 9 10 11 12 def TicketGroup (num ): if (num >= 2 )&(num <= 4 ): return 0 elif (num == 1 )|((num >=5 )&(num <= 8 )): return 1 else : return 2 data['TicketGroup' ] = data['TicketCount' ].map (TicketGroup) sns.barplot(data = data,x = 'TicketGroup' ,y = 'Survived' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a2586a940>
图表解析 :与上面分析结果基本一致,TicketGroup较小,也就是TicketCount大概在1-4之间时,存活率最高
未完待续~
以上是对泰坦尼克生存预测案例的一部分分析,剩余部分为Age的缺失值处理,以及预测模型的构建,也就是算法部分,目前对算法的了解尚浅,能力不足以处理,待补充。对以上分析有疑义,欢迎指正,感谢阅读~