摘要
项目描述 项目名称 :CDNow在线音乐零售平台用户消费行为分析
项目背景 :CDNow是一家网络公司,经营着一个在线购物网站,主要销售光盘和音乐相关产品。2000年7月,被Bertelsmann Music Group 以1.17亿美元收购;而后不久,由亚马逊承包经营。本文主要通过分析CDNow网站的用户购买明细数据来分析该网站的用户消费行为,使运营部门在营销时更具有针对性,从而节省成本,提高效率。
字段说明
用户ID:用户身份唯一标识(数据集中一个用户ID有多条消费记录)
购买日期:即消费日期
订单数:购买数量
订单金额:总消费金额
项目目的 :
数据处理 数据加载 1 2 3 4 5 6 7 8 9 10 11 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as ssimport warnings%matplotlib inline import osos.chdir("/home/min/data" ) warnings.filterwarnings("ignore" )
1 2 3 4 5 colums = ['用户ID' ,'购买日期' ,'订单数' ,'订单金额' ] data = pd.read_csv("CDNOW.txt" ,names = colums,sep="\s+" ) data.head()
用户ID
购买日期
订单数
订单金额
0
1
19970101
1
11.77
1
2
19970112
1
12.00
2
2
19970112
5
77.00
3
3
19970102
2
20.76
4
3
19970330
2
20.76
数据查看
用户ID
购买日期
订单数
订单金额
count
69659.000000
6.965900e+04
69659.000000
69659.000000
mean
11470.854592
1.997228e+07
2.410040
35.893648
std
6819.904848
3.837735e+03
2.333924
36.281942
min
1.000000
1.997010e+07
1.000000
0.000000
25%
5506.000000
1.997022e+07
1.000000
14.490000
50%
11410.000000
1.997042e+07
2.000000
25.980000
75%
17273.000000
1.997111e+07
3.000000
43.700000
max
23570.000000
1.998063e+07
99.000000
1286.010000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 69659 entries, 0 to 69658
Data columns (total 4 columns):
用户ID 69659 non-null int64
购买日期 69659 non-null int64
订单数 69659 non-null int64
订单金额 69659 non-null float64
dtypes: float64(1), int64(3)
memory usage: 2.1 MB
数据类型转换 & 添加字段 1 2 3 4 data['购买日期' ] = pd.to_datetime(data['购买日期' ],format ='%Y%m%d' ) data['月份' ] = data['购买日期' ].values.astype('datetime64[M]' )
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 69659 entries, 0 to 69658
Data columns (total 5 columns):
用户ID 69659 non-null int64
购买日期 69659 non-null datetime64[ns]
订单数 69659 non-null int64
订单金额 69659 non-null float64
月份 69659 non-null datetime64[ns]
dtypes: datetime64[ns](2), float64(1), int64(2)
memory usage: 2.7 MB
用户ID
购买日期
订单数
订单金额
月份
0
1
1997-01-01
1
11.77
1997-01-01
1
2
1997-01-12
1
12.00
1997-01-01
2
2
1997-01-12
5
77.00
1997-01-01
3
3
1997-01-02
2
20.76
1997-01-01
4
3
1997-03-30
2
20.76
1997-03-01
1 2 3 data.apply(lambda x:sum (x.isnull()))
用户ID 0
购买日期 0
订单数 0
订单金额 0
月份 0
dtype: int64
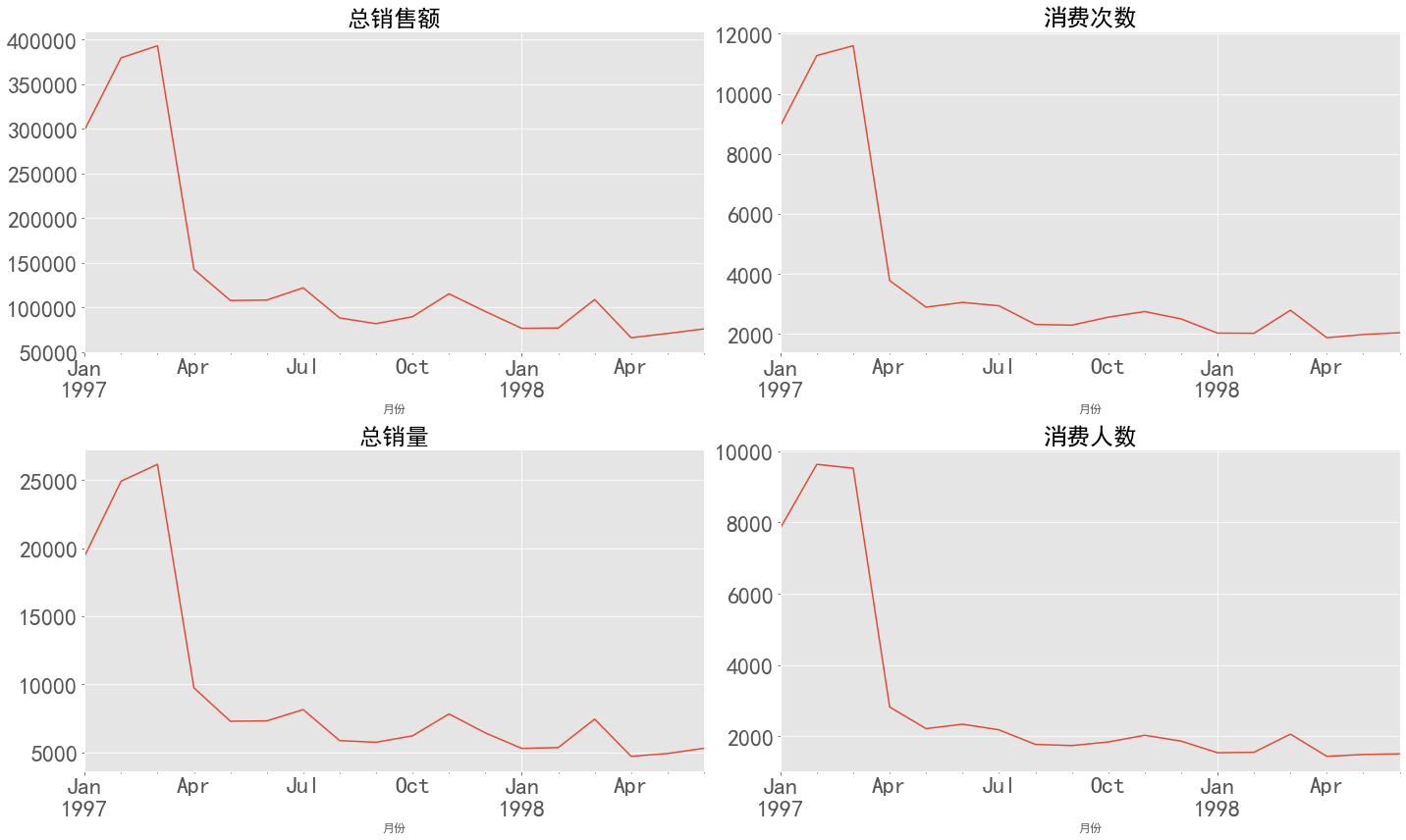
用户消费分析 用户总体消费趋势 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 plt.style.use('ggplot' ) plt.figure(figsize = (20 ,12 )) plt.subplot(221 ) data.groupby('月份' )['订单金额' ].sum ().plot(fontsize = 24 ) plt.title('总销售额' ,fontsize = 24 ) plt.subplot(222 ) data.groupby('月份' )['购买日期' ].count().plot(fontsize = 24 ) plt.title('消费次数' ,fontsize = 24 ) plt.subplot(223 ) data.groupby('月份' )['订单数' ].sum ().plot(fontsize = 24 ) plt.title('总销量' ,fontsize = 24 ) plt.subplot(224 ) data.groupby('月份' )['用户ID' ].apply(lambda x:len (x.unique())).plot(fontsize = 24 ) plt.title('消费人数' ,fontsize = 24 ) plt.tight_layout() plt.show()
图表解析 :四个折线图趋势基本一致,呈现为前3个月销量极高,销售额暴涨,往后骤然下降,最后趋于平稳。
消费金额在前三个月达到最高峰,后期消费金额较为平稳,呈小幅度下降趋势
前三个月消费次数在10000左右,往后月份消费次数基本维持在2500
产品购买量趋势呈现为早起购买量多 后期小幅度下降趋势
每月消费人数小于每月的消费次数(订单数),但是区别不大,前三个月每月的消费人数在8000-10000之间,后续月份平均2000左右,一样是前期消费人数多,后期平稳下降趋势
出现这种状况,假设问题是出现在用户身上,早期时间段的用户有异常值,或者由于各类促销营销,由于只有消费数据,无法进一步进行判断
1 2 3 4 5 6 7 data.pivot_table(index='月份' , values=['订单数' ,'订单金额' ,'用户ID' ], aggfunc={'订单数' :'sum' , '订单金额' :'sum' , '用户ID' :'count' })
用户ID
订单数
订单金额
月份
1997-01-01
8928
19416
299060.17
1997-02-01
11272
24921
379590.03
1997-03-01
11598
26159
393155.27
1997-04-01
3781
9729
142824.49
1997-05-01
2895
7275
107933.30
1997-06-01
3054
7301
108395.87
1997-07-01
2942
8131
122078.88
1997-08-01
2320
5851
88367.69
1997-09-01
2296
5729
81948.80
1997-10-01
2562
6203
89780.77
1997-11-01
2750
7812
115448.64
1997-12-01
2504
6418
95577.35
1998-01-01
2032
5278
76756.78
1998-02-01
2026
5340
77096.96
1998-03-01
2793
7431
108970.15
1998-04-01
1878
4697
66231.52
1998-05-01
1985
4903
70989.66
1998-06-01
2043
5287
76109.30
用户个体消费分析 用户消费金额 & 消费次数 1 2 3 4 5 6 7 group_user = data.groupby('用户ID' ).sum () group_user.describe()
订单数
订单金额
count
23570.000000
23570.000000
mean
7.122656
106.080426
std
16.983531
240.925195
min
1.000000
0.000000
25%
1.000000
19.970000
50%
3.000000
43.395000
75%
7.000000
106.475000
max
1033.000000
13990.930000
图表解析 :
用户平均购买7张CD,而标准差为17,说明波动较大;中位值只有3,更是说明了存在小部分用户购买了大数量的CD
用户平均消费金额106,中位值是43,也说明了存在极值干扰
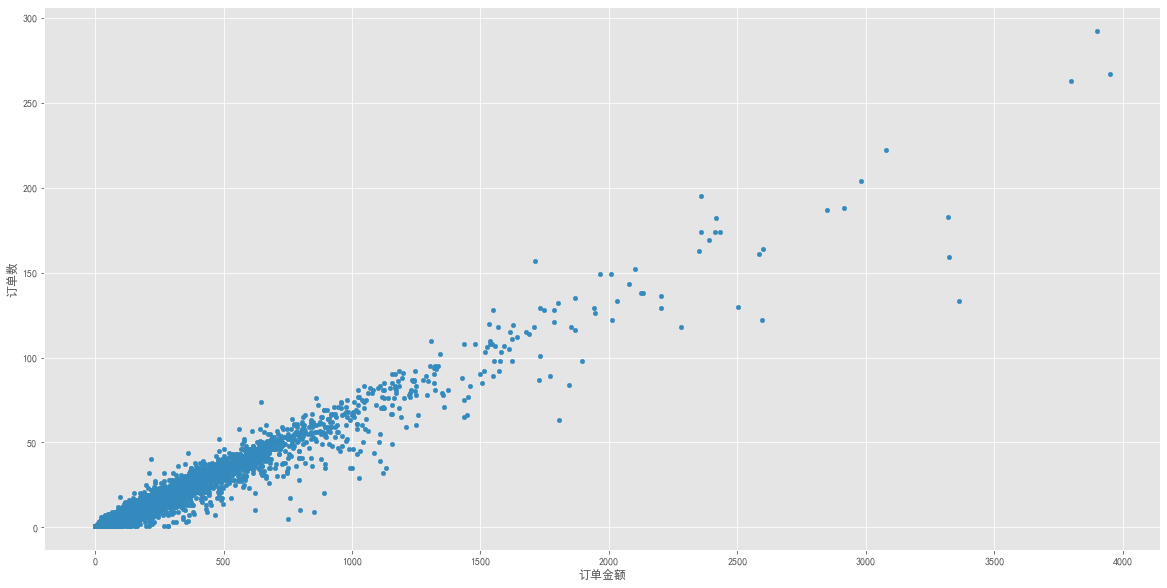
用户消费金额 & 购买数量(散点图) 1 2 3 group_user.query('订单金额 < 4000' ).plot.scatter(x = '订单金额' ,y = '订单数' ,figsize = (20 ,10 ))
图表解析 :由于数据源是CD网站的销售数据,商品种类单一,金额和商品量呈线性,并不存在大量离群点。
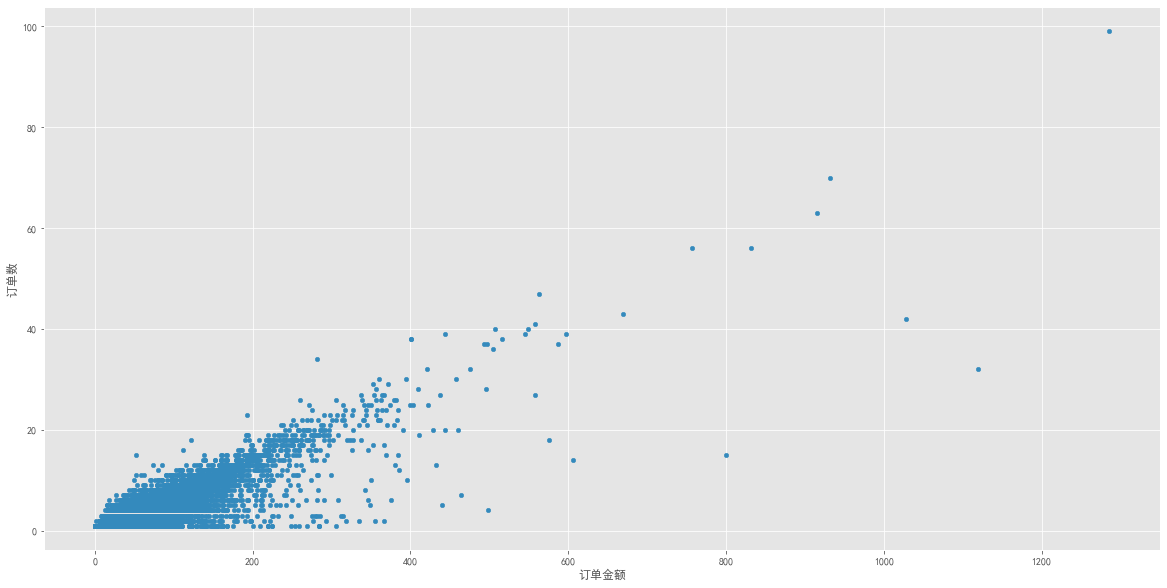
1 2 3 data.plot.scatter(x = '订单金额' ,y = '订单数' ,figsize = (20 ,10 ))
图表解析 :从订单角度分析,订单消费金额多数在0~400,而每笔订单购买数量大多在0~40,而且订单购买数量极值极少,基本与上方用户消费角度分析趋势一致。
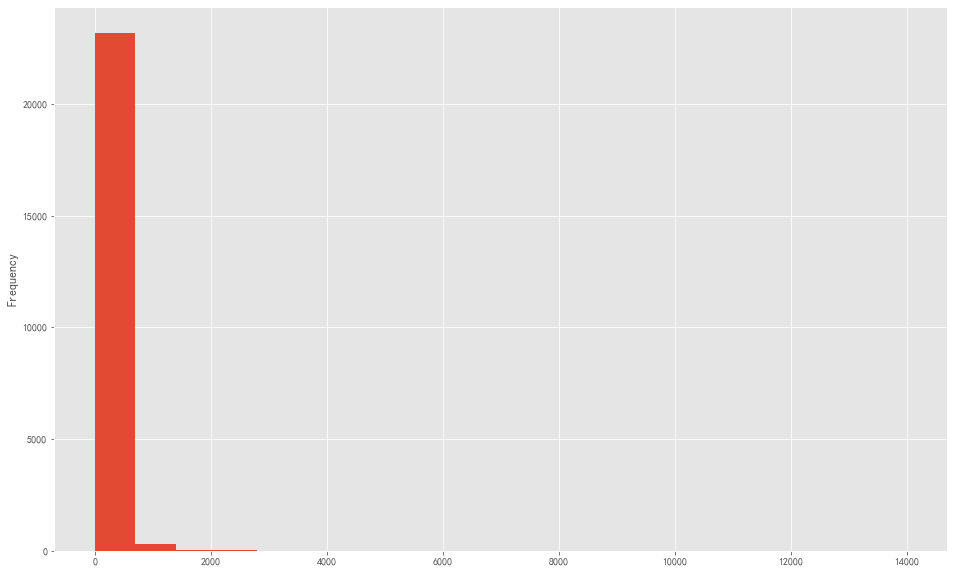
消费金额分布 1 2 3 group_user['订单金额' ].plot.hist(bins = 20 ,figsize = (16 ,10 ))
图表解析 :用户大部分消费能力不高,基本上绝大部分用户处于很低的消费档次,图中基本看不到高消费用户。
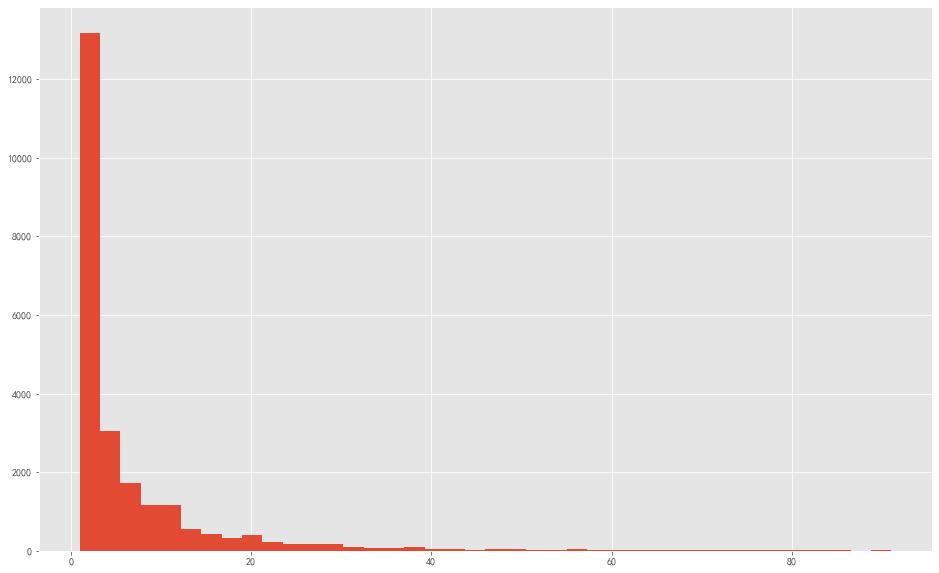
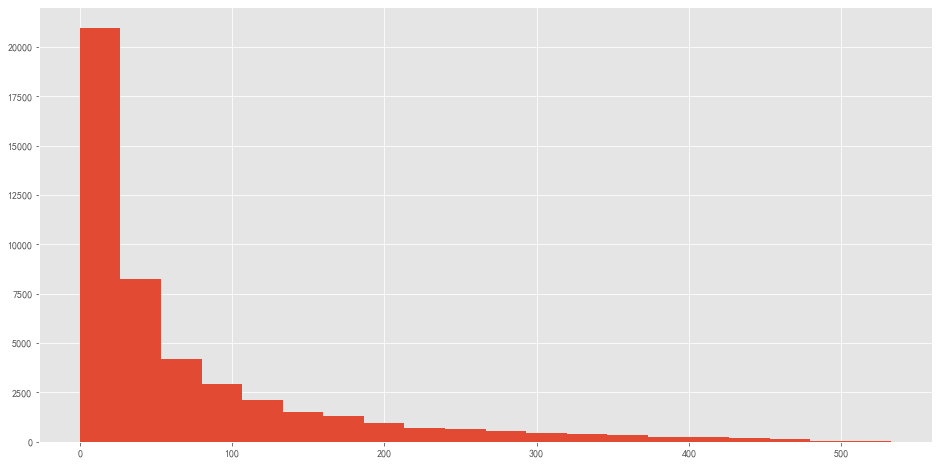
用户消费次数 1 2 3 group_user.query('订单数 < 92' )['订单数' ].hist(bins = 40 ,figsize = (16 ,10 ))
图表解析 :排除部分极值干扰,可看出大部分用户购买CD的数量都在3张以内,购买大数量的用户属极少数。
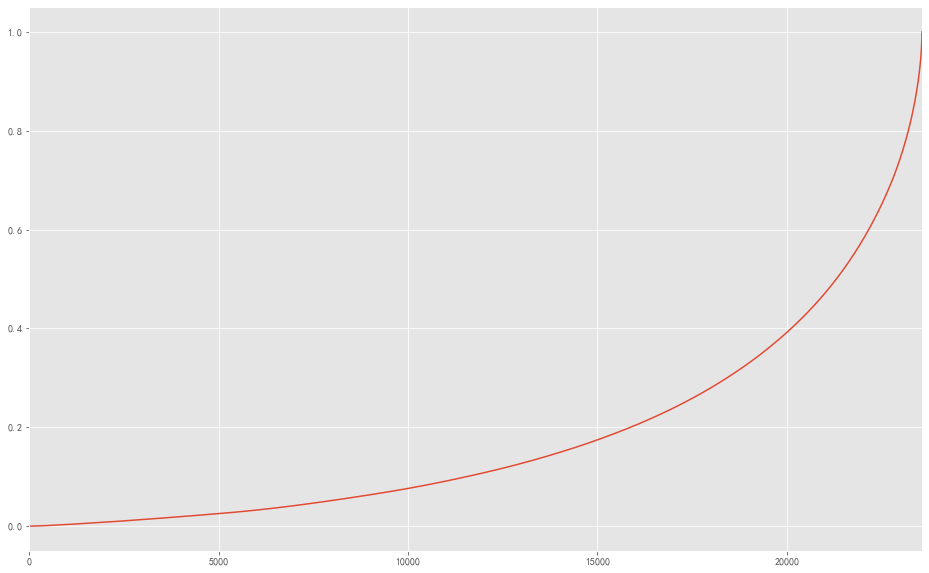
用户累计消费金额占比 1 2 3 4 user_cumsum = group_user.sort_values('订单金额' ).apply(lambda x:x.cumsum() / x.sum ()) user_cumsum.reset_index()['订单金额' ].plot(figsize = (16 ,10 ))
图表解析 :50%的用户仅贡献了15%的消费额,而排名前5000的用户就贡献了60%的消费金额。
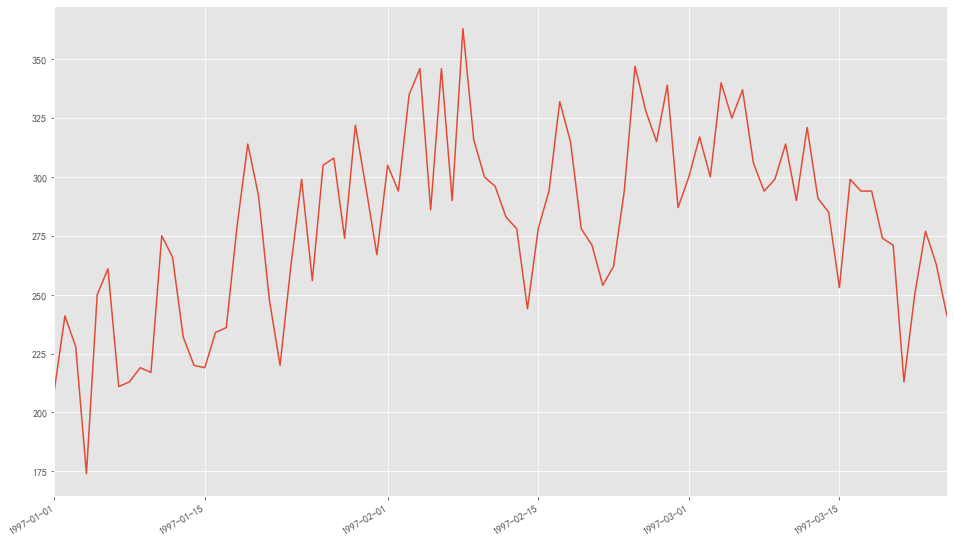
用户消费周期 用户首购时间 1 2 3 4 orderdt_min = data.groupby('用户ID' ).min ()['购买日期' ] orderdt_min.value_counts().plot(figsize = (16 ,10 ))
**图表解析:**用户第一次购买基本集中在前三个月,而在2月份中下旬有一次较大的波动
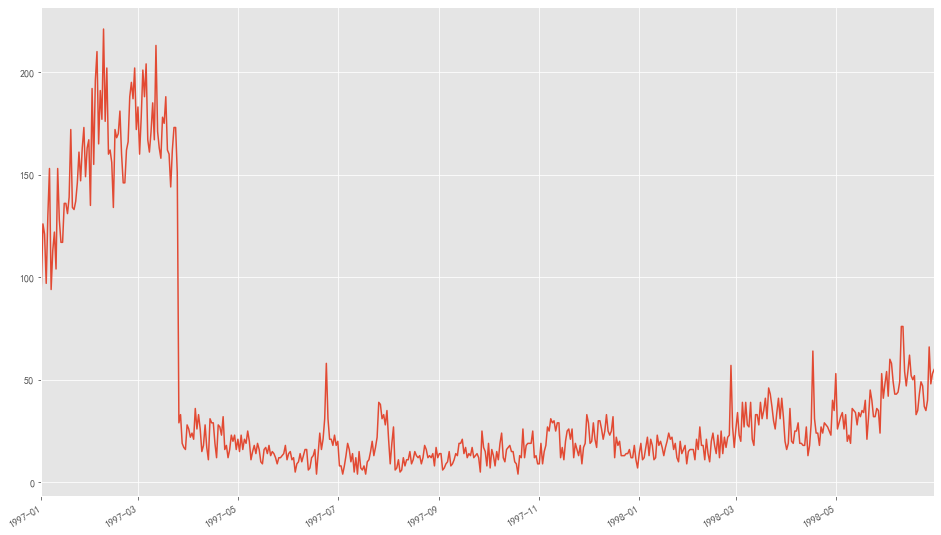
用户最后一次购买时间 1 2 3 4 orderdt_max = data.groupby('用户ID' ).max ()['购买日期' ] orderdt_max.value_counts().plot(figsize = (16 ,10 ))
图表解析:
用户最后一次购买的分布比第一次购买分布要广
大部分最后一次购买在前三个月,说明很多用户购买一次之后就不再消费
往后月份,最后一次购买数呈小幅度递增,有上升趋势
用户分层 RFM模型分层 构建RFM模型 1 2 3 4 5 6 rfm = data.pivot_table(index = '用户ID' , values=['订单数' ,'订单金额' ,'购买日期' ], aggfunc={'购买日期' :'max' , '订单金额' :'sum' , '订单数' :'sum' }) rfm.head()
订单数
订单金额
购买日期
用户ID
1
1
11.77
1997-01-01
2
6
89.00
1997-01-12
3
16
156.46
1998-05-28
4
7
100.50
1997-12-12
5
29
385.61
1998-01-03
1 -(rfm['购买日期' ] - rfm['购买日期' ].max ()).head()
用户ID
1 545 days
2 534 days
3 33 days
4 200 days
5 178 days
Name: 购买日期, dtype: timedelta64[ns]
1 2 3 4 5 rfm['R' ] = -(rfm['购买日期' ] - rfm['购买日期' ].max ()) / np.timedelta64(1 ,'D' ) rfm.rename(columns={'订单数' :'F' ,'订单金额' :'M' },inplace=True ) rfm.head()
F
M
购买日期
R
用户ID
1
1
11.77
1997-01-01
545.0
2
6
89.00
1997-01-12
534.0
3
16
156.46
1998-05-28
33.0
4
7
100.50
1997-12-12
200.0
5
29
385.61
1998-01-03
178.0
1 rfm[['R' ,'F' ,'M' ]].apply(lambda x:x-x.mean()).head()
R
F
M
用户ID
1
177.778362
-6.122656
-94.310426
2
166.778362
-1.122656
-17.080426
3
-334.221638
8.877344
50.379574
4
-167.221638
-0.122656
-5.580426
5
-189.221638
21.877344
279.529574
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def rfm_func (x ): level = x.apply(lambda x:'1' if x>=0 else '0' ) label = level.R + level.F + level.M d = { '111' :'重要价值客户' , '011' :'重要保持客户' , '101' :'重要挽留客户' , '001' :'重要发展客户' , '110' :'一般价值客户' , '010' :'一般保持客户' , '100' :'一般挽留客户' , '000' :'一般发展客户' , } result = d[label] return result rfm['label' ] = rfm[['R' ,'F' ,'M' ]].apply(lambda x:x-x.mean()).apply(rfm_func,axis = 1 ) rfm.head()
F
M
购买日期
R
label
用户ID
1
1
11.77
1997-01-01
545.0
一般挽留客户
2
6
89.00
1997-01-12
534.0
一般挽留客户
3
16
156.46
1998-05-28
33.0
重要保持客户
4
7
100.50
1997-12-12
200.0
一般发展客户
5
29
385.61
1998-01-03
178.0
重要保持客户
1 rfm.groupby('label' ).sum ()
F
M
R
label
一般价值客户
650
7181.28
36295.0
一般保持客户
1712
19937.45
29448.0
一般发展客户
13977
196971.23
591108.0
一般挽留客户
29346
438291.81
6951815.0
重要价值客户
11121
167080.83
358363.0
重要保持客户
107789
1592039.62
517267.0
重要发展客户
2023
45785.01
56636.0
重要挽留客户
1263
33028.40
114482.0
1 rfm.groupby('label' ).count()
F
M
购买日期
R
label
一般价值客户
77
77
77
77
一般保持客户
206
206
206
206
一般发展客户
3300
3300
3300
3300
一般挽留客户
14074
14074
14074
14074
重要价值客户
787
787
787
787
重要保持客户
4554
4554
4554
4554
重要发展客户
331
331
331
331
重要挽留客户
241
241
241
241
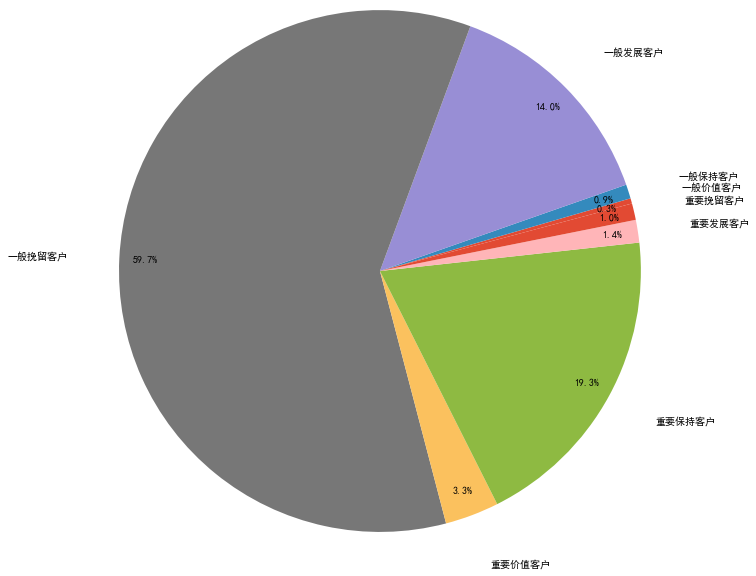
1 2 3 4 5 6 7 8 9 10 11 12 13 user_t = rfm.groupby('label' ).count() plt.axis('equal' ) labels = ['一般价值客户' ,'一般保持客户' ,'一般发展客户' ,'一般挽留客户' ,'重要价值客户' ,'重要保持客户' ,'重要发展客户' ,'重要挽留客户' ] plt.pie(user_t['M' ], autopct='%3.1f%%' , labels=labels, pctdistance=0.9 , labeldistance=1.2 , radius = 3 , startangle=15 ) plt.show()
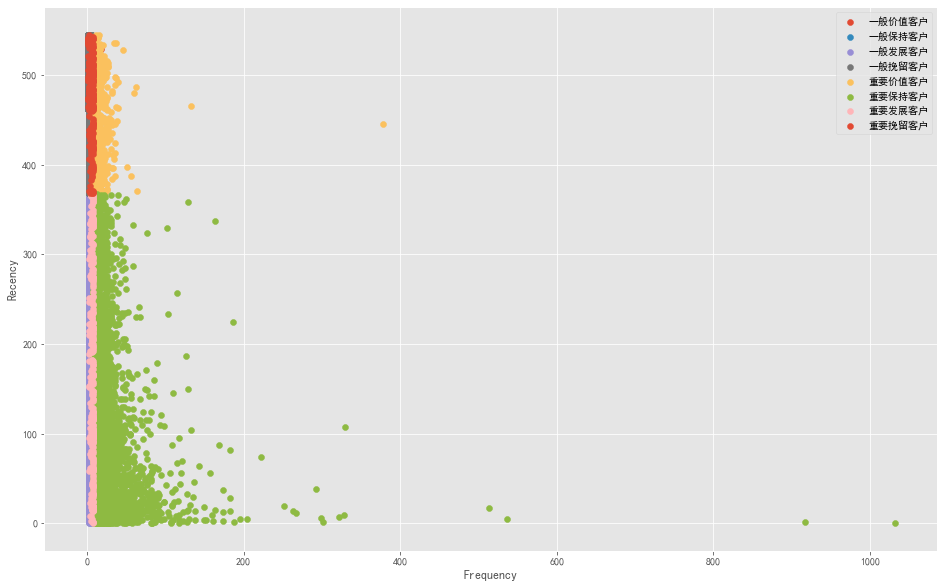
1 2 3 4 5 6 7 8 9 10 plt.figure(figsize=(16 ,10 )) for label,grouped in rfm.groupby('label' ): x = grouped['F' ] y = grouped['R' ] plt.scatter(x,y,label = label) plt.legend(loc = 'best' ) plt.xlabel('Frequency' ) plt.ylabel('Recency' ) plt.show()
图表解析 :可以看出,大部分用户为重要保持客户,原因可能是存在极值,也说明了RFM模型的划分应该依照业务的实际情况来进行划分层级。
活跃度分层 按照活跃度分层用户 1 2 3 4 5 6 7 8 9 pivoted_counts = data.pivot_table(index='用户ID' , columns='月份' , values='购买日期' , aggfunc='count' ).fillna(0 ) pivoted_counts.columns = data['月份' ].sort_values().astype('str' ).unique() pivoted_counts.head()
1997-01-01
1997-02-01
1997-03-01
1997-04-01
1997-05-01
1997-06-01
1997-07-01
1997-08-01
1997-09-01
1997-10-01
1997-11-01
1997-12-01
1998-01-01
1998-02-01
1998-03-01
1998-04-01
1998-05-01
1998-06-01
用户ID
1
1.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
2
2.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
3
1.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
2.0
0.0
0.0
0.0
0.0
0.0
1.0
0.0
4
2.0
0.0
0.0
0.0
0.0
0.0
0.0
1.0
0.0
0.0
0.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
5
2.0
1.0
0.0
1.0
1.0
1.0
1.0
0.0
1.0
0.0
0.0
2.0
1.0
0.0
0.0
0.0
0.0
0.0
1 2 data_purchase = pivoted_counts.applymap(lambda x:1 if x>0 else 0 ) data_purchase.tail()
1997-01-01
1997-02-01
1997-03-01
1997-04-01
1997-05-01
1997-06-01
1997-07-01
1997-08-01
1997-09-01
1997-10-01
1997-11-01
1997-12-01
1998-01-01
1998-02-01
1998-03-01
1998-04-01
1998-05-01
1998-06-01
用户ID
23566
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
23567
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
23568
0
0
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
23569
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
23570
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def active_status (data ): status = [] for i in range (18 ): if data[i] == 0 : if len (status) > 0 : if status[i-1 ] == 'unreg' : status.append('unreg' ) else : status.append('unactive' ) else : status.append('unreg' ) else : if len (status) == 0 : status.append('new' ) else : if status[i-1 ] == 'unactive' : status.append('return' ) elif status[i-1 ] == 'unreg' : status.append('new' ) else : status.append('active' ) return pd.Series(status,data_purchase.columns)
1 2 purchase_states = data_purchase.apply(active_status,axis = 1 ) purchase_states.tail()
1997-01-01
1997-02-01
1997-03-01
1997-04-01
1997-05-01
1997-06-01
1997-07-01
1997-08-01
1997-09-01
1997-10-01
1997-11-01
1997-12-01
1998-01-01
1998-02-01
1998-03-01
1998-04-01
1998-05-01
1998-06-01
用户ID
23566
unreg
unreg
new
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
23567
unreg
unreg
new
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
23568
unreg
unreg
new
active
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
23569
unreg
unreg
new
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
23570
unreg
unreg
new
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
unactive
1 2 3 4 5 6 7 8 purchase_states_m = purchase_states.replace('unreg' ,np.NaN).apply(lambda x:pd.value_counts(x)) purchase_states_m = purchase_states_m.fillna(0 ).T purchase_states_m
active
new
return
unactive
1997-01-01
0.0
7846.0
0.0
0.0
1997-02-01
1157.0
8476.0
0.0
6689.0
1997-03-01
1681.0
7248.0
595.0
14046.0
1997-04-01
1773.0
0.0
1049.0
20748.0
1997-05-01
852.0
0.0
1362.0
21356.0
1997-06-01
747.0
0.0
1592.0
21231.0
1997-07-01
746.0
0.0
1434.0
21390.0
1997-08-01
604.0
0.0
1168.0
21798.0
1997-09-01
528.0
0.0
1211.0
21831.0
1997-10-01
532.0
0.0
1307.0
21731.0
1997-11-01
624.0
0.0
1404.0
21542.0
1997-12-01
632.0
0.0
1232.0
21706.0
1998-01-01
512.0
0.0
1025.0
22033.0
1998-02-01
472.0
0.0
1079.0
22019.0
1998-03-01
571.0
0.0
1489.0
21510.0
1998-04-01
518.0
0.0
919.0
22133.0
1998-05-01
459.0
0.0
1029.0
22082.0
1998-06-01
446.0
0.0
1060.0
22064.0
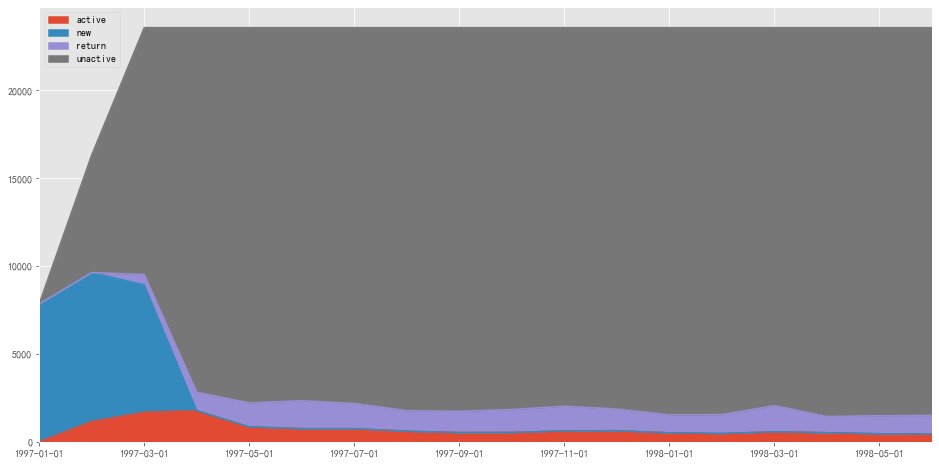
1 2 purchase_states_m.plot.area(figsize = (16 ,8 )) plt.show()
图表解析 :
蓝色和灰色区域占了绝大部分面积,推断为某段时间消费过的用户的后续行为
红色部分代表的活跃用户较为稳定,属于核心用户
紫色部分代表的回流用户也表现的较为稳定
回流用户占比
回流用户比:某个时间段内回流用户在总用户中的占比
回流用户率:相比上月有多少不活跃用户在本月进行了消费
活跃用户比:某个时间段内活跃用户在总用户中的占比
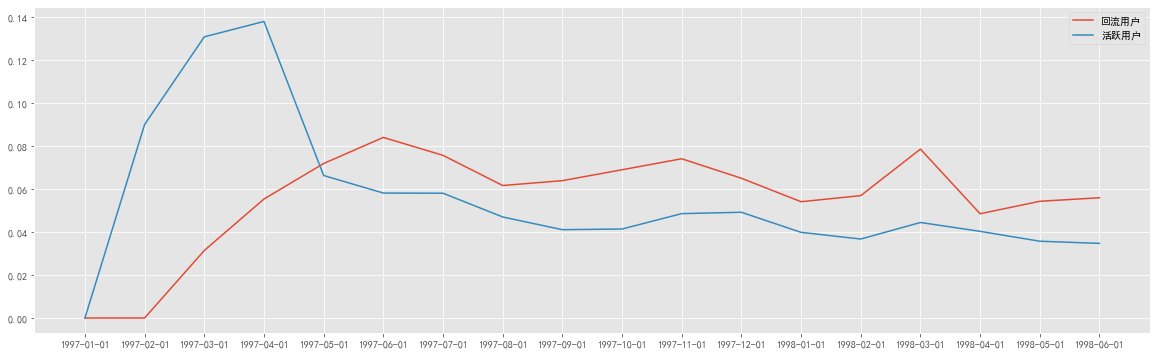
1 2 3 4 5 6 plt.figure(figsize=(20 ,6 )) rate = purchase_states_m.apply(lambda x: x/x.sum ()) plt.plot(rate['return' ],label = '回流用户' ) plt.plot(rate['active' ],label = '活跃用户' ) plt.legend() plt.show()
图表解析 :
用户每月回流用户比在5%~8%之间,且有小幅度下降趋势,说明客户有流失可能
数据源中不活跃用户量基本保持不变,所以回流率近似于回流比
活跃用户的占比基本稳定在3%~5%之间,下降趋势更明显
结合活跃用户和回流用户,在后期的消费用户中,近60%是回流用户,40%为活跃用户,说明整体用户质量相对不错。
用户质量分析 用户购买周期 1 2 order_diff = data.groupby('用户ID' ).apply(lambda x: x['购买日期' ] - x['购买日期' ].shift()) order_diff.head(10 )
用户ID
1 0 NaT
2 1 NaT
2 0 days
3 3 NaT
4 87 days
5 3 days
6 227 days
7 10 days
8 184 days
4 9 NaT
Name: 购买日期, dtype: timedelta64[ns]
count 46089
mean 68 days 23:22:13.567662
std 91 days 00:47:33.924168
min 0 days 00:00:00
25% 10 days 00:00:00
50% 31 days 00:00:00
75% 89 days 00:00:00
max 533 days 00:00:00
Name: 购买日期, dtype: object
1 2 3 4 (order_diff / np.timedelta64(1 ,'D' )).hist(bins = 20 ,figsize = (16 ,8 )) plt.show()
图表解析 :
订单周期呈指数分布
用户的平均购买周期是68天,而且大多数用户的购买周期低于100天
从图像看属于典型的长尾图,说明绝大部分用户的消费间隔较短。可以考虑将时间召回点设为消费后立即赠送优惠券,且在消费后10天左右对客户进行回访,消费后30天后提醒优惠券即将到期,消费后60天短信推送进行尝试召回。
用户生命周期 1 2 user_life = data.groupby('用户ID' )['购买日期' ].agg(['min' ,'max' ]) user_life.head()
min
max
用户ID
1
1997-01-01
1997-01-01
2
1997-01-12
1997-01-12
3
1997-01-02
1998-05-28
4
1997-01-01
1997-12-12
5
1997-01-01
1998-01-03
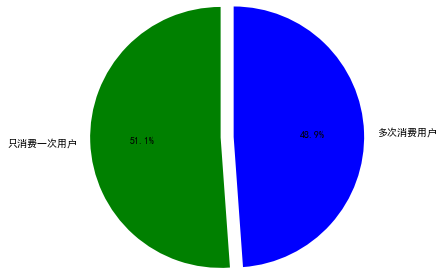
用户消费占比 仅消费一次用户占比 1 2 3 4 5 6 7 8 user_once = (user_life['min' ] == user_life['max' ]).value_counts() labels = ['只消费一次用户' ,'多次消费用户' ] plt.axis('equal' ) plt.pie(user_once,explode=(0 ,0.15 ),labels=labels,autopct='%2.1f%%' ,startangle=90 , colors=('g' ,'blue' ),radius=1.5 ) plt.show()
1 2 3 (user_life['max' ] - user_life['min' ]).describe()
count 23570
mean 134 days 20:55:36.987696
std 180 days 13:46:43.039788
min 0 days 00:00:00
25% 0 days 00:00:00
50% 0 days 00:00:00
75% 294 days 00:00:00
max 544 days 00:00:00
dtype: object
图表解析 :
仅消费一次的用户占比为51.1%,进行多次消费用户占比48.9%.
而通过描述可知,用户的平均生命周期为134天,但中位数为0,说明大部分用户第一次消费也是最后一次,所以平均生命周期并不具有准确性。
用户生命周期最大值为544天,几乎等同于数据源总天数,代表这部分用户属于忠实拥护者,也是核心用户。
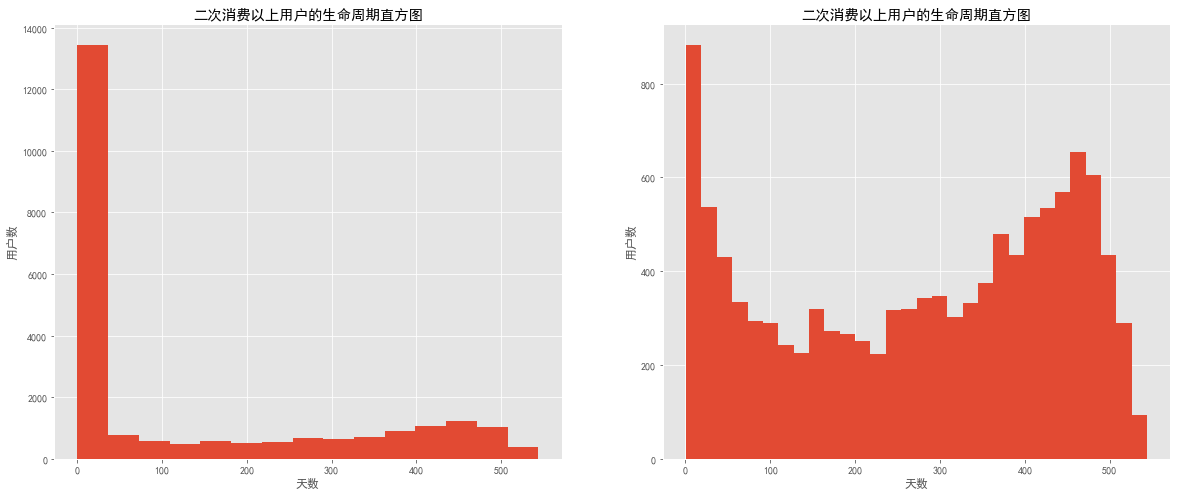
消费多次用户周期分布 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 plt.figure(figsize=(20 ,8 )) plt.subplot(121 ) ((user_life['max' ] - user_life['min' ]) / np.timedelta64(1 ,'D' )).hist(bins = 15 ) plt.title('二次消费以上用户的生命周期直方图' ) plt.xlabel('天数' ) plt.ylabel('用户数' ) plt.subplot(122 ) user_twice = ((user_life['max' ] - user_life['min' ]).reset_index()[0 ] / np.timedelta64(1 ,'D' )) user_twice[user_twice > 0 ].hist(bins = 30 ) plt.title('二次消费以上用户的生命周期直方图' ) plt.xlabel('天数' ) plt.ylabel('用户数' ) plt.show()
图表解析 :通过对比可知,去除周期为0的用户后,图像呈双峰结构。
右图为过滤后的生命周期分布图,但仍然存在生命周期趋于0天的用户,说明部分低质量用户,虽然消费过两次,但并不能持续消费。需要在消费后短时间内进行再次消费引导。
少部分用户集中在50~300天之间,忠诚度一般。
另一个高峰出现在400天之后,这部分用户属于高质量用户,忠诚度较高,而且后期用户数还在增加,需要维护这批用户的利益,长期保持回访、让利。
1 2 3 user_twice[user_twice > 0 ].mean()
276.0448072247308
图表解析 :消费两次以上的用户平均生命周期为276天,远高于总体平均生命周期。所以在用户首次消费后进行引导及召回可以很有效提高用户的生命周期。
复购率 & 回购率分析 复购率
1997-01-01
1997-02-01
1997-03-01
1997-04-01
1997-05-01
1997-06-01
1997-07-01
1997-08-01
1997-09-01
1997-10-01
1997-11-01
1997-12-01
1998-01-01
1998-02-01
1998-03-01
1998-04-01
1998-05-01
1998-06-01
用户ID
1
1.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
2
2.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
3
1.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
2.0
0.0
0.0
0.0
0.0
0.0
1.0
0.0
4
2.0
0.0
0.0
0.0
0.0
0.0
0.0
1.0
0.0
0.0
0.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
5
2.0
1.0
0.0
1.0
1.0
1.0
1.0
0.0
1.0
0.0
0.0
2.0
1.0
0.0
0.0
0.0
0.0
0.0
1 2 3 4 5 purchare_r = pivoted_counts.applymap(lambda x: 1 if x > 1 else np.NaN if x == 0 else 0 ) purchare_r.head()
1997-01-01
1997-02-01
1997-03-01
1997-04-01
1997-05-01
1997-06-01
1997-07-01
1997-08-01
1997-09-01
1997-10-01
1997-11-01
1997-12-01
1998-01-01
1998-02-01
1998-03-01
1998-04-01
1998-05-01
1998-06-01
用户ID
1
0.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2
1.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
3
0.0
NaN
0.0
0.0
NaN
NaN
NaN
NaN
NaN
NaN
1.0
NaN
NaN
NaN
NaN
NaN
0.0
NaN
4
1.0
NaN
NaN
NaN
NaN
NaN
NaN
0.0
NaN
NaN
NaN
0.0
NaN
NaN
NaN
NaN
NaN
NaN
5
1.0
0.0
NaN
0.0
0.0
0.0
0.0
NaN
0.0
NaN
NaN
1.0
0.0
NaN
NaN
NaN
NaN
NaN
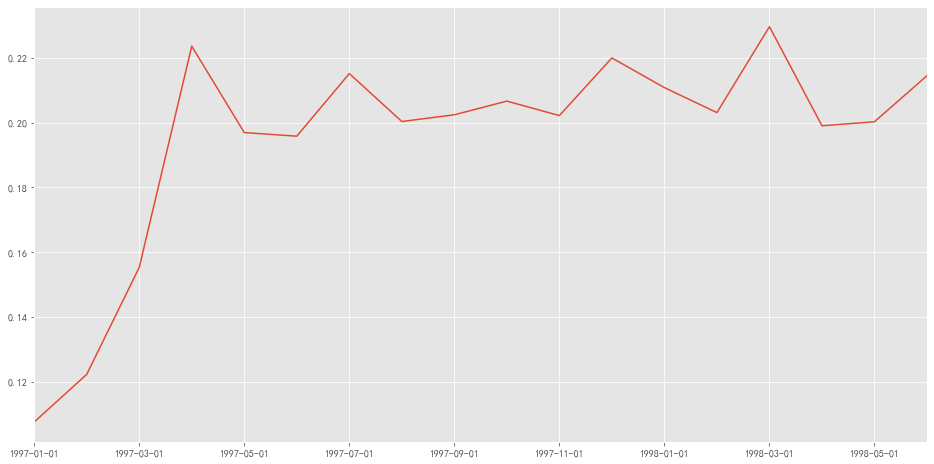
1 2 3 4 (purchare_r.sum () / purchare_r.count()).plot(figsize = (16 ,8 )) plt.show()
图表解析 :复购率稳定在20%~22%,而前三个月复购率低,可能是有大量新用户所导致。
回购率
回购率 – 曾经购买的用户在某一时期内的再次购买占比
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def purchare_back (data ): status = [] for i in range (17 ): if data[i] == 1 : if data[i+1 ] == 1 : status.append(1 ) if data[i+1 ] == 0 : status.append(0 ) else : status.append(np.NaN) status.append(np.NaN) return pd.Series(status,data_purchase.columns)
1 2 purchare_b = data_purchase.apply(purchare_back,axis = 1 ) purchare_b.head()
1997-01-01
1997-02-01
1997-03-01
1997-04-01
1997-05-01
1997-06-01
1997-07-01
1997-08-01
1997-09-01
1997-10-01
1997-11-01
1997-12-01
1998-01-01
1998-02-01
1998-03-01
1998-04-01
1998-05-01
1998-06-01
用户ID
1
0.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2
0.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
3
0.0
NaN
1.0
0.0
NaN
NaN
NaN
NaN
NaN
NaN
0.0
NaN
NaN
NaN
NaN
NaN
0.0
NaN
4
0.0
NaN
NaN
NaN
NaN
NaN
NaN
0.0
NaN
NaN
NaN
0.0
NaN
NaN
NaN
NaN
NaN
NaN
5
1.0
0.0
NaN
1.0
1.0
1.0
0.0
NaN
0.0
NaN
NaN
1.0
0.0
NaN
NaN
NaN
NaN
NaN
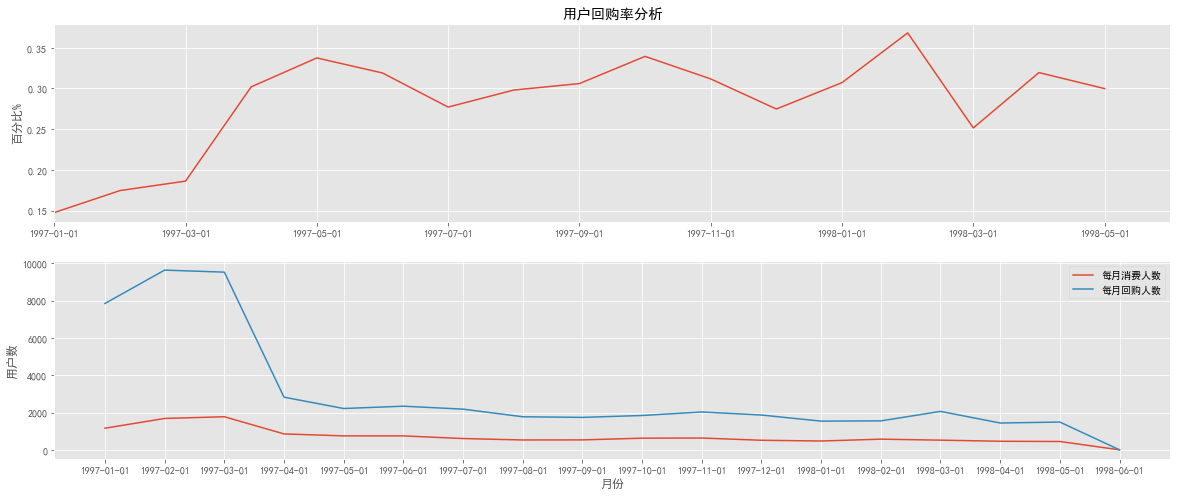
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 plt.figure(figsize = (20 ,8 )) plt.subplot(211 ) (purchare_b.sum () / purchare_b.count()).plot() plt.title('用户回购率分析' ) plt.ylabel('百分比%' ) plt.subplot(212 ) plt.plot(purchare_b.sum (),label = '每月消费人数' ) plt.plot(purchare_b.count(),label = '每月回购人数' ) plt.xlabel('月份' ) plt.ylabel('用户数' ) plt.legend() plt.show()
图表分析 :
回购率基本稳定在25%~35%,较高于复购率,但波动性较大。新用户回购率在15%左右,与老用户相差不大
从消费人数分布图可以发现,回购人数在前三个月后趋于稳定,所以波动的原因有可能是营销淡旺季所导致
结合回购率复购率,可以看出新用户的整体忠诚度低于老用户,而老用户回购率较高,消费频次较低。
留存率分析 1 2 user_purchare = data[['用户ID' ,'订单数' ,'订单金额' ,'购买日期' ]] user_purchare.head()
用户ID
订单数
订单金额
购买日期
0
1
1
11.77
1997-01-01
1
2
1
12.00
1997-01-12
2
2
5
77.00
1997-01-12
3
3
2
20.76
1997-01-02
4
3
2
20.76
1997-03-30
1 2 3 4 5 6 7 user_purchare_retention = pd.merge(left = user_purchare, right = user_life['min' ].reset_index(), how = 'inner' , on = '用户ID' ) user_purchare_retention['order_dt_diff' ] = user_purchare_retention['购买日期' ] - user_purchare_retention['min' ] user_purchare_retention['dt_diff' ] = user_purchare_retention.order_dt_diff.apply(lambda x: x / np.timedelta64(1 ,'D' )) user_purchare_retention.head()
用户ID
订单数
订单金额
购买日期
min
order_dt_diff
dt_diff
0
1
1
11.77
1997-01-01
1997-01-01
0 days
0.0
1
2
1
12.00
1997-01-12
1997-01-12
0 days
0.0
2
2
5
77.00
1997-01-12
1997-01-12
0 days
0.0
3
3
2
20.76
1997-01-02
1997-01-02
0 days
0.0
4
3
2
20.76
1997-03-30
1997-01-02
87 days
87.0
1 2 3 4 5 bin = [0 ,30 ,60 ,90 ,120 ,150 ,180 ,365 ]user_purchare_retention['date_diff_bin' ] = pd.cut(user_purchare_retention.dt_diff,bins = bin ) user_purchare_retention.head(10 )
用户ID
订单数
订单金额
购买日期
min
order_dt_diff
dt_diff
date_diff_bin
0
1
1
11.77
1997-01-01
1997-01-01
0 days
0.0
NaN
1
2
1
12.00
1997-01-12
1997-01-12
0 days
0.0
NaN
2
2
5
77.00
1997-01-12
1997-01-12
0 days
0.0
NaN
3
3
2
20.76
1997-01-02
1997-01-02
0 days
0.0
NaN
4
3
2
20.76
1997-03-30
1997-01-02
87 days
87.0
(60.0, 90.0]
5
3
2
19.54
1997-04-02
1997-01-02
90 days
90.0
(60.0, 90.0]
6
3
5
57.45
1997-11-15
1997-01-02
317 days
317.0
(180.0, 365.0]
7
3
4
20.96
1997-11-25
1997-01-02
327 days
327.0
(180.0, 365.0]
8
3
1
16.99
1998-05-28
1997-01-02
511 days
511.0
NaN
9
4
2
29.33
1997-01-01
1997-01-01
0 days
0.0
NaN
1 2 pivoted_retention = user_purchare_retention.pivot_table(index='用户ID' ,columns='date_diff_bin' ,values='订单金额' ,aggfunc=sum ) pivoted_retention.head()
date_diff_bin
(0, 30]
(30, 60]
(60, 90]
(90, 120]
(120, 150]
(150, 180]
(180, 365]
用户ID
3
NaN
NaN
40.3
NaN
NaN
NaN
78.41
4
29.73
NaN
NaN
NaN
NaN
NaN
41.44
5
13.97
38.90
NaN
45.55
38.71
26.14
155.54
7
NaN
NaN
NaN
NaN
NaN
NaN
97.43
8
NaN
13.97
NaN
NaN
NaN
45.29
104.17
1 pivoted_retention.mean()
date_diff_bin
(0, 30] 51.540649
(30, 60] 50.215070
(60, 90] 48.975277
(90, 120] 48.649005
(120, 150] 51.399450
(150, 180] 49.932592
(180, 365] 91.960059
dtype: float64
1 2 pivoted_retention_trans = pivoted_retention.fillna(0 ).applymap(lambda x: 1 if x>0 else 0 ) pivoted_retention_trans.head()
date_diff_bin
(0, 30]
(30, 60]
(60, 90]
(90, 120]
(120, 150]
(150, 180]
(180, 365]
用户ID
3
0
0
1
0
0
0
1
4
1
0
0
0
0
0
1
5
1
1
0
1
1
1
1
7
0
0
0
0
0
0
1
8
0
1
0
0
0
1
1
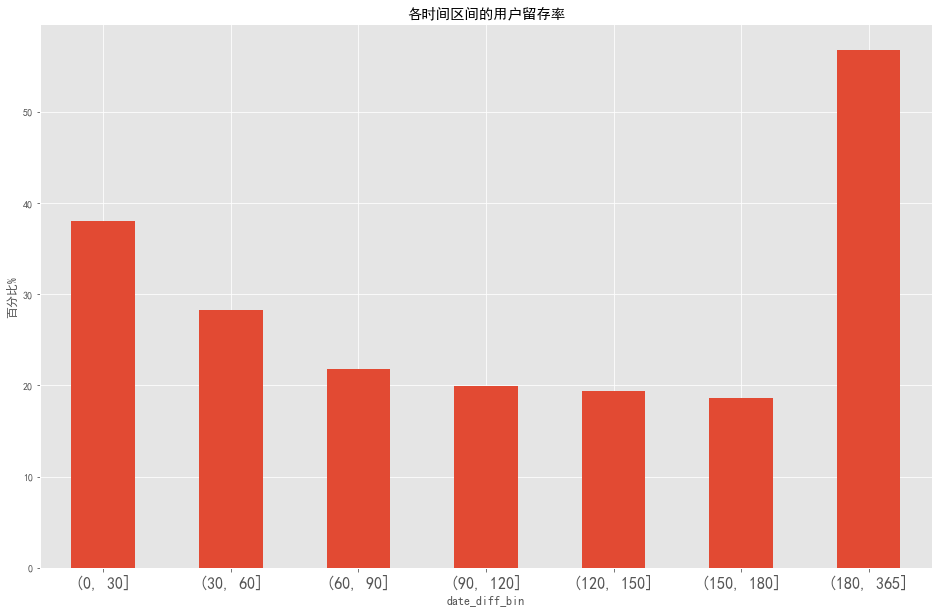
1 2 3 4 5 ((pivoted_retention_trans.sum () / pivoted_retention_trans.count()) * 100 ).plot.bar(figsize = (16 ,10 )) plt.ylabel('百分比%' ) plt.xticks(fontsize = 16 ,rotation = 360 ) plt.title('各时间区间的用户留存率' ) plt.show()
图表解析 :
第一个月的留存率达到了38%,历经两个月下滑,之后趋于稳定。说明用户在通过前三个月的使用,逐渐出现分歧,即部分用户成为忠实用户,剩余部分用户流失。有20%左右的用户在第一次购买后的三个月到半年之间有过再次消费,27%的用户在半年后至一年内进行了再次购买。
相比于拉新而言,应该更注重用户忠诚度的培养。如果进行活动,应该放在前三个月。
结合用户生命周期,用户的平均消费时间间隔为68天,所以应该在60天左右的间隔对用户进行召回和引导。
写在最后 以上为CDNow网站用户消费行为分析的全部内容,有错误之处,恳请指正。感谢阅读!