摘要
深度挖掘天猫双十一时刻的美妆产品销售数据,分析各品牌之间的销量、热度、价格等~
项目描述
项目名称:天猫双十一美妆产品销售数据分析
数据来源:数据来源于网络,为2016年双十一美妆产品天猫数据的采集和整理,原始数据为.xlsx格式。
字段说明:
update_time : 更新时间
id : 商品id(唯一标识)
title : 商品标题
price : 价格
店名 : 即品牌名
项目目的:
通过对数据集进行清理整合,并进行以下几个方面的分析:
- 双十一期间各品牌的销量以及销售额对比
- 各大品牌热度
- 各品牌价格分析
- 关于男性护肤品销量分析
- 消费高峰期分析
环境解释:基于jupyter notebook,可视化工具包:matplotlib、seaborn
数据导入
1 | # 导入模块 |
1 | # 数据读取 |
1 | # 数据基本属性 |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27598 entries, 0 to 27597
Data columns (total 7 columns):
update_time 27598 non-null object
id 27598 non-null object
title 27598 non-null object
price 27598 non-null float64
sale_count 25244 non-null float64
comment_count 25244 non-null float64
店名 27598 non-null object
dtypes: float64(3), object(4)
memory usage: 1.5+ MB
1 | # 店名统计 |
悦诗风吟 3021
佰草集 2265
欧莱雅 1974
雅诗兰黛 1810
倩碧 1704
美加净 1678
欧珀莱 1359
妮维雅 1329
相宜本草 1313
兰蔻 1285
娇兰 1193
自然堂 1190
玉兰油 1135
兰芝 1091
美宝莲 825
资生堂 821
植村秀 750
薇姿 746
雅漾 663
雪花秀 543
SKII 469
蜜丝佛陀 434
Name: 店名, dtype: int64
数据清洗
清除重复数据
1 | # drop_duplicates -- 重复数据 |
(27512, 7)
索引重构
1 | # 重置索引 |
日期处理
1 | # 日期处理 |
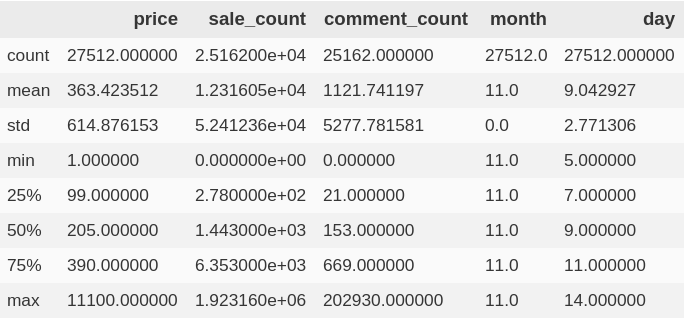
1 | # 查看数据描述性统计 |
1 | # 查看缺失值 |
update_time 0
id 0
title 0
price 0
sale_count 2350
comment_count 2350
店名 0
date 0
month 0
day 0
dtype: int64
1 | data.isnull().any() |
update_time False
id False
title False
price False
sale_count True
comment_count True
店名 False
date False
month False
day False
dtype: bool
缺失值处理
1 | # sale_count & comment_count 考虑使用众数填充 |
0 0.0
dtype: float64
1 | data['sale_count'] = data['sale_count'].fillna(0) |
1 | # 再次确认缺失值 |
update_time 0
id 0
title 0
price 0
sale_count 0
comment_count 0
店名 0
date 0
month 0
day 0
dtype: int64
1 | data.duplicated().value_counts() |
False 27512
dtype: int64
信息提取
表格信息提取
1 | # 表格信息提取 |
1 | title_cut = [] |
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 1.520 seconds.
Prefix dict has been built successfully.
1 | data['item_name_cut'] = title_cut |
添加商品类别
1 | # 给商品添加分类 |
1 | category_config_map = {} |
1 | # 查看主类别 & 子类别 |
{'乳液': ('护肤品', '乳液类'),
'美白乳': ('护肤品', '乳液类'),
'润肤乳': ('护肤品', '乳液类'),
'凝乳': ('护肤品', '乳液类'),
"柔肤液'": ('护肤品', '乳液类'),
'亮肤乳': ('护肤品', '乳液类'),
'菁华乳': ('护肤品', '乳液类'),
'眼霜': ('护肤品', '眼部护理'),
'眼部精华': ('护肤品', '眼部护理'),
'洗面': ('护肤品', '清洁类'),
'洁面': ('护肤品', '清洁类'),
'清洁': ('护肤品', '清洁类'),
'卸妆': ('护肤品', '清洁类'),
'洁颜': ('护肤品', '清洁类'),
'洗颜': ('护肤品', '清洁类'),
'去角质': ('护肤品', '清洁类'),
'化妆水': ('护肤品', '化妆水'),
'爽肤水': ('护肤品', '化妆水'),
'柔肤水': ('护肤品', '化妆水'),
'补水露': ('护肤品', '化妆水'),
'凝露': ('护肤品', '化妆水'),
'柔肤液': ('护肤品', '化妆水'),
'精粹水': ('护肤品', '化妆水'),
'亮肤水': ('护肤品', '化妆水'),
'润肤水': ('护肤品', '化妆水'),
'保湿水': ('护肤品', '化妆水'),
'菁华水': ('护肤品', '化妆水'),
'保湿喷雾': ('护肤品', '化妆水'),
'面霜': ('护肤品', '面霜类'),
'日霜': ('护肤品', '面霜类'),
'晚霜': ('护肤品', '面霜类'),
'柔肤霜': ('护肤品', '面霜类'),
'滋润霜': ('护肤品', '面霜类'),
'保湿霜': ('护肤品', '面霜类'),
'凝霜': ('护肤品', '面霜类'),
'日间霜': ('护肤品', '面霜类'),
'晚间霜': ('护肤品', '面霜类'),
'乳霜': ('护肤品', '面霜类'),
'修护霜': ('护肤品', '面霜类'),
'亮肤霜': ('护肤品', '面霜类'),
'底霜': ('护肤品', '面霜类'),
'精华液': ('护肤品', '精华类'),
'精华水': ('护肤品', '精华类'),
'精华露': ('护肤品', '精华类'),
'防晒霜': ('护肤品', '防晒类'),
'唇釉': ('化妆品', '口红类'),
'口红': ('化妆品', '口红类'),
'散粉': ('化妆品', '底妆类'),
'蜜粉': ('化妆品', '底妆类'),
'粉底液': ('化妆品', '底妆类'),
'定妆粉 ': ('化妆品', '底妆类'),
'气垫': ('化妆品', '底妆类'),
'粉饼': ('化妆品', '底妆类'),
'BB': ('化妆品', '底妆类'),
'CC': ('化妆品', '底妆类'),
'遮瑕': ('化妆品', '底妆类'),
'粉霜': ('化妆品', '底妆类'),
'粉底膏': ('化妆品', '底妆类'),
'眉粉': ('化妆品', '眼部彩妆'),
'染眉膏': ('化妆品', '眼部彩妆'),
'眼线': ('化妆品', '眼部彩妆'),
'眼影': ('化妆品', '眼部彩妆'),
'鼻影': ('化妆品', '修容类'),
'修容粉': ('化妆品', '修容类'),
'高光': ('化妆品', '修容类')}
1 | # 分类处理 |
新增主类别 & 子类别
1 | # 新增 子类别 & 主类别 两列 |
1 | # 子类别统计 |
其他 13100
清洁类 2922
面霜类 2675
化妆水 1955
底妆类 1790
乳液类 1352
眼部护理 1114
精华类 727
口红类 715
眼部彩妆 604
防晒类 494
修容类 64
Name: sub_type, dtype: int64
1 | # 主类别统计 |
其他 13100
护肤品 11239
化妆品 3173
Name: main_type, dtype: int64
新增 “是否为男士专用” 类别
1 | # 新增 "是否为男士专用" 列 |
1 | data['是否男士专用'] = gender |
否 25310
是 2202
Name: 是否男士专用, dtype: int64
新增销售额 & 购买日期
1 | # 新增 销售额 & 购买日期(天) 两列 |
1 | # 时间格式转换 |
0 2016-11-14
1 2016-11-14
2 2016-11-14
3 2016-11-14
4 2016-11-14
...
27507 2016-11-05
27508 2016-11-05
27509 2016-11-05
27510 2016-11-05
27511 2016-11-05
Name: update_time, Length: 27512, dtype: datetime64[ns]
时间列类型装换 & 新增以天为单位时间列
1 | # 将时间列设置为新的index & 新增时间列 "天" |
1 | del data['item_name_cut'] |
1 | # 清理后数据查看 |
1 | data.info() |
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 27512 entries, 2016-11-14 to 2016-11-05
Data columns (total 13 columns):
id 27512 non-null object
title 27512 non-null object
price 27512 non-null float64
sale_count 27512 non-null float64
comment_count 27512 non-null float64
店名 27512 non-null object
date 27512 non-null datetime64[ns]
month 27512 non-null int64
day 27512 non-null int64
sub_type 27512 non-null object
main_type 27512 non-null object
是否男士专用 27512 non-null object
销售额 27512 non-null float64
dtypes: datetime64[ns](1), float64(4), int64(2), object(6)
memory usage: 2.9+ MB
1 | # 数据备份 |
分析及可视化
各品牌SKU数
SKU : Stock Keeping Unit。SKU是库存量单位,区分单品。
在电商领域,通常每一个商品详情页对应一个独立的SKU编码。
1 | # 图表风格 |
1 | plt.figure(figsize=(16,10)) |
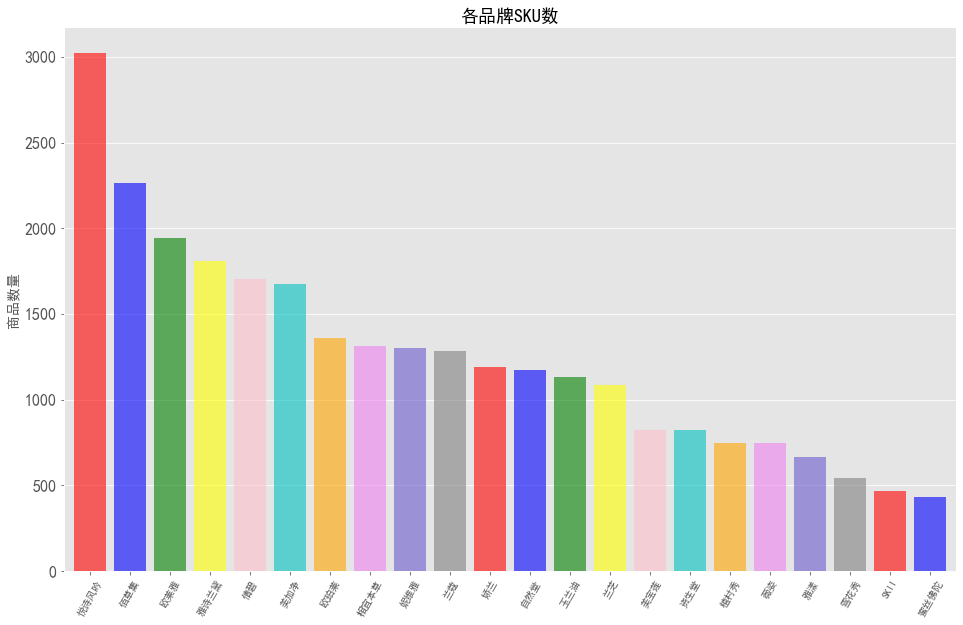
图表解析:由图可知,仅悦诗风吟与佰草集的商品数量超过两千,且悦诗风吟商品数量达到了3000+,稳居榜首。
各品牌销量&销售额
1 | fig,axes = plt.subplots(1,2,figsize=(24,12)) |
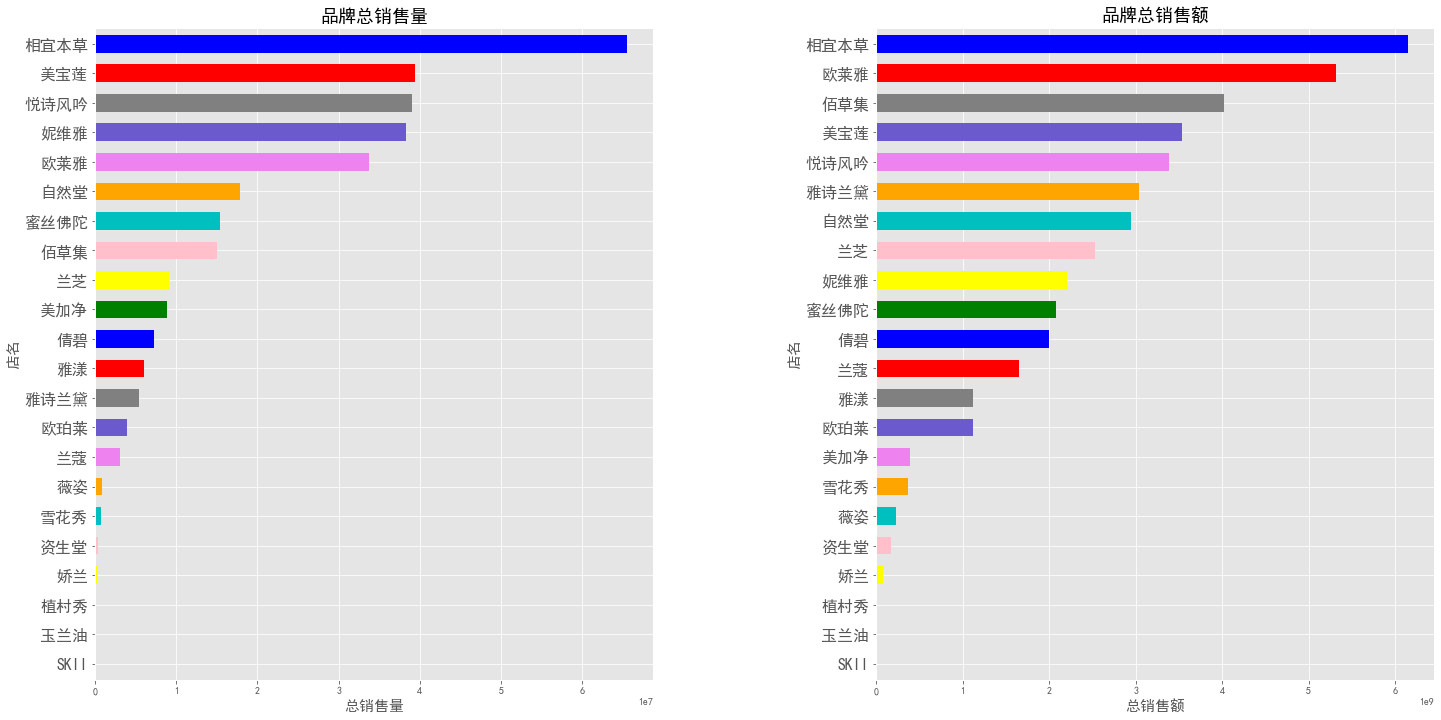
图表解析:相宜本草的销售量和销售额都是最高的。销量第二至第五,分别为美宝莲、悦诗风吟、妮维雅和欧莱雅;而销售额第二至第五,分别为欧莱雅、佰草集、美宝莲、悦诗风吟。其中,美宝莲、悦诗风吟和欧莱雅都在销量&销售额前五内。
各类别销售量
1 | # 各类别的销售量占比情况 |
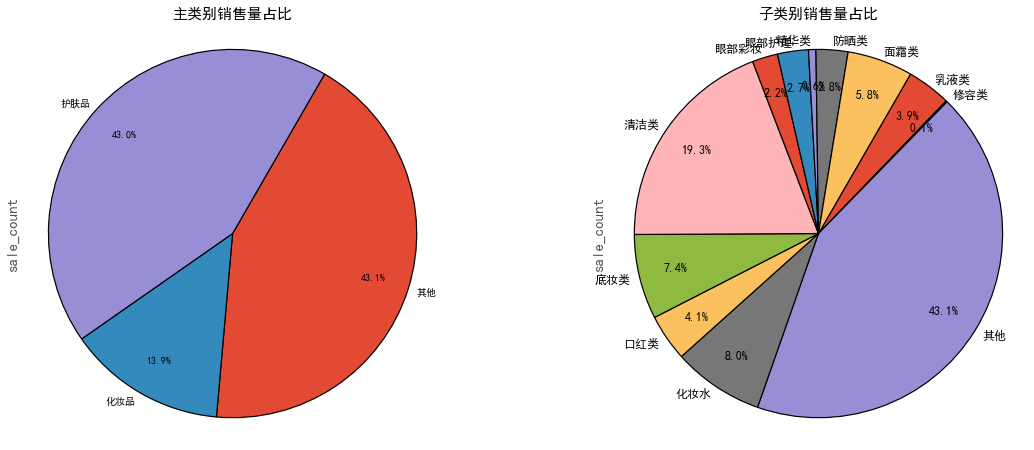
图表解析:
- 从主类别销售量占比情况来看,护肤品的销量远大于化妆品销量
- 从子类别销售量占比情况来看,底妆类、口红类在化妆品中销量最多,清洁类、化妆水、面霜在护肤品中销量最多。
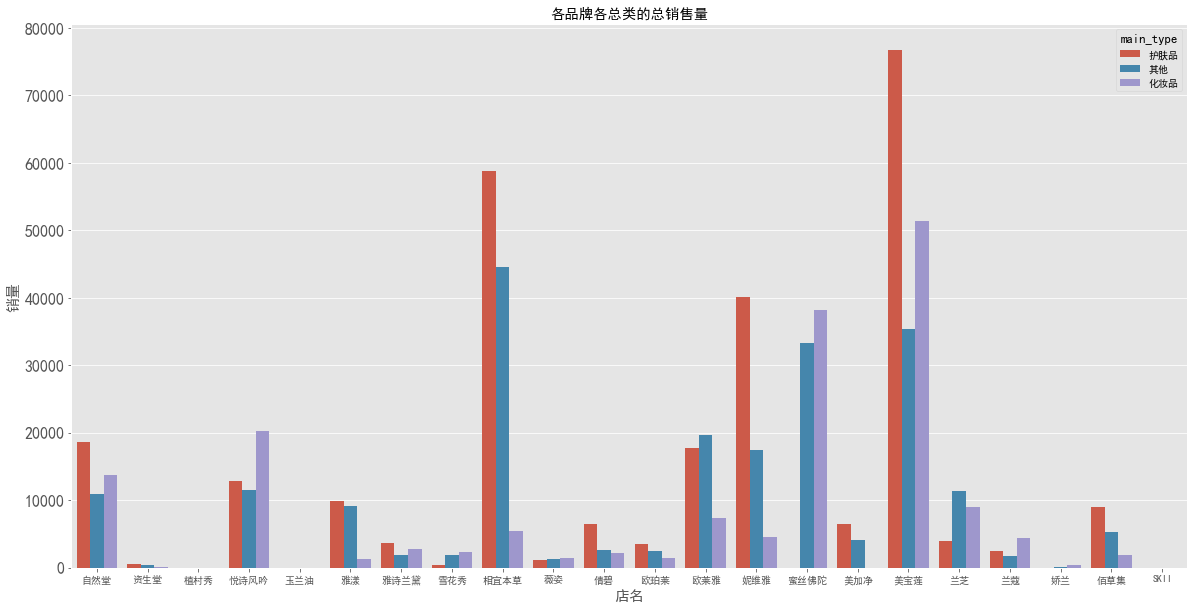
各品牌销量 - 主类别
1 | # 销量 |
各品牌销售额 - 主类别
1 | # 销售额 |
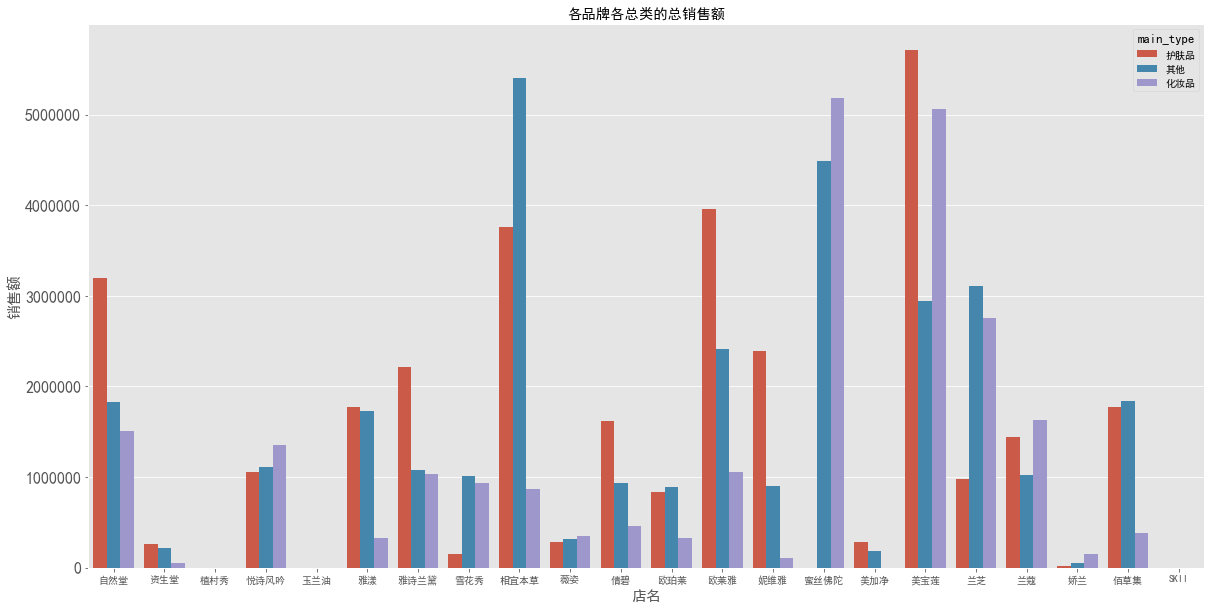
图表解析:各品牌的化妆品、护肤品销量以及销售情况均不一样,可能与品牌的定位有关。有的品牌主打化妆品,化妆品销量、销售额表现会相对好很多,例如蜜丝佛陀等;而主打护肤品的品牌,护肤品的销量、销售额会表现较好,如欧莱雅、佰草集等;也有部分品牌如美宝莲、兰蔻、悦诗风吟,化妆品和护肤品的销量、销售额都还不错。
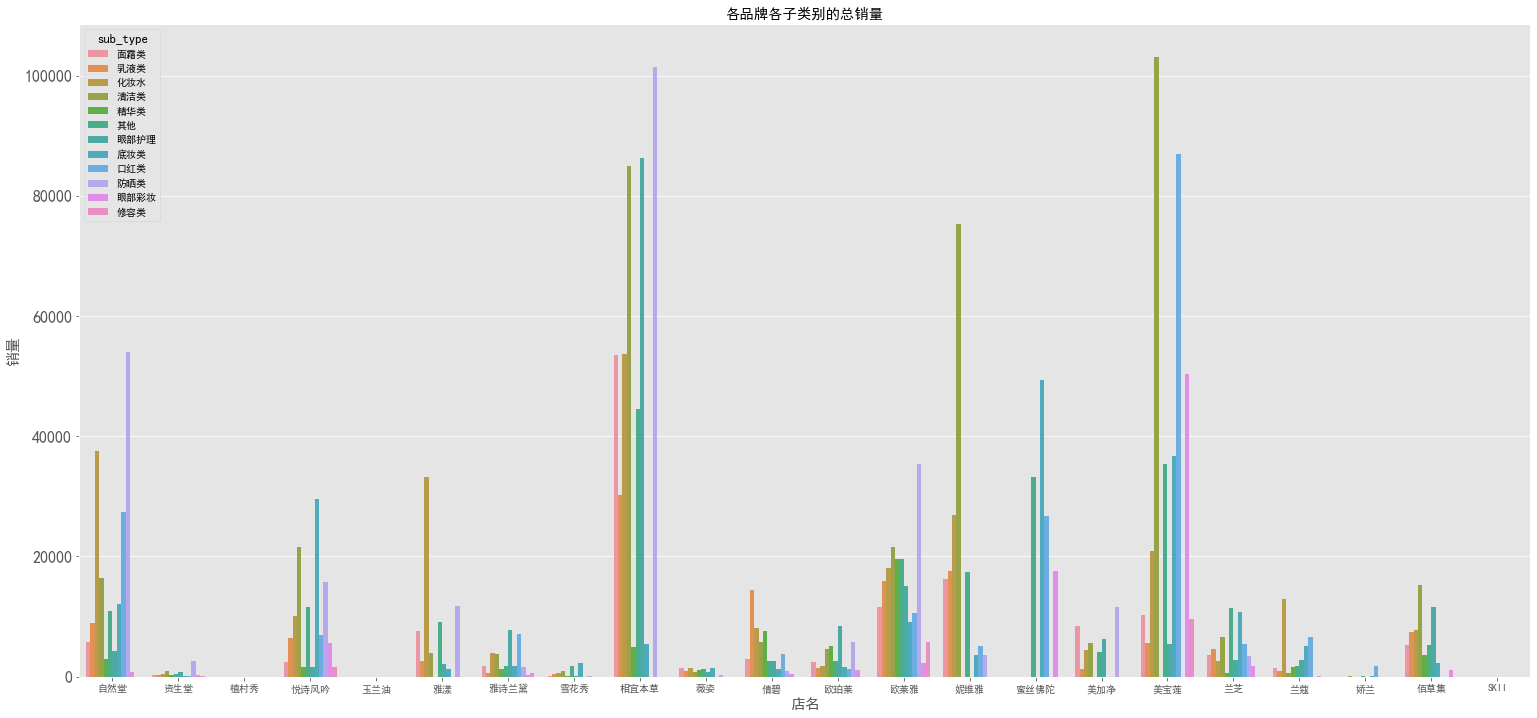
各品牌销量 - 子类别
1 | # 各品牌各子类销量 |
各品牌销售额 - 子类别
1 | plt.figure(figsize=(26,15)) |
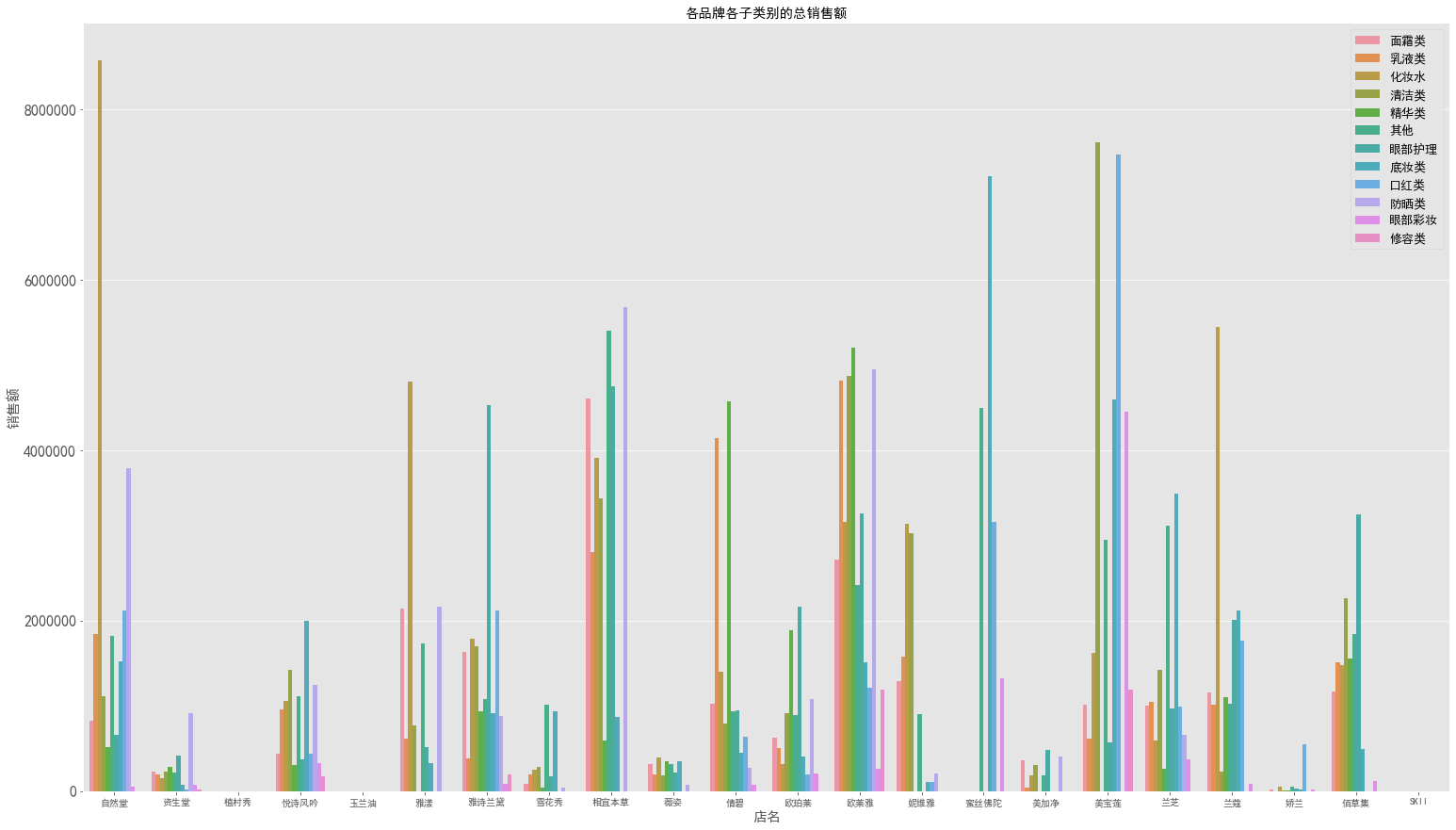
图表解析:由于子类别较多,图表大致上能呈现出与主类别数据分析结果一致,其中比较突出的是自然堂的化妆水的销售额在自然堂总销售额中占据极大份额。
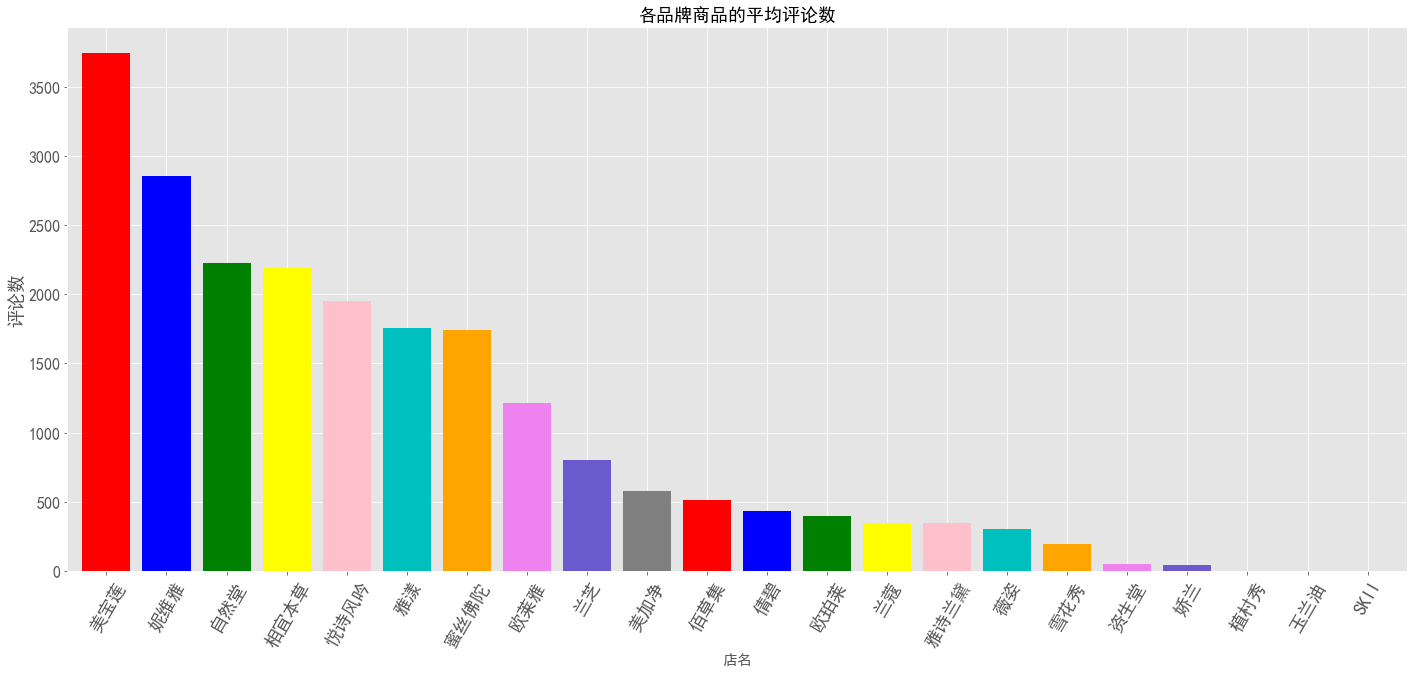
品牌热度
根据数据源分析,本次品牌热度呈现主要根据各品牌商品的平均评论数多少来展现。
1 | # 各品牌热度 |
1 | # 销量热度 |
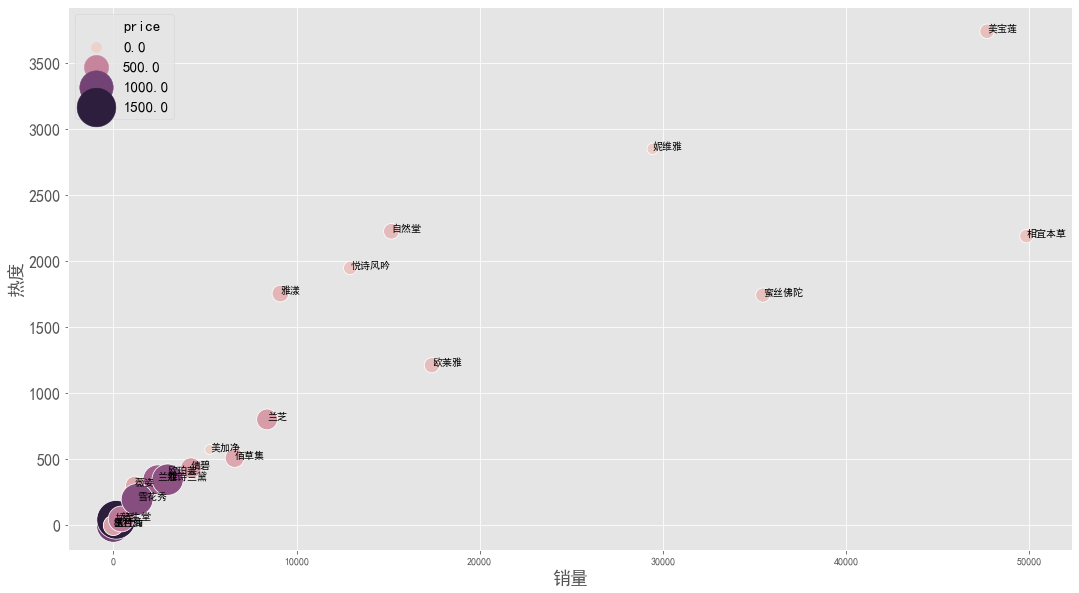
图表解析:
热度越高的品牌越靠上,销量越高的品牌越靠右,价格越高的品牌颜色越深圈越大
- 热度与销量呈一定的正相关
- 美宝莲热度第一,销量第二;妮维雅热度第二,销量第四;且二者价格均相对较低
- 图中显示,价格低的品牌热度和销量相对较高,价格高的品牌热度和销量相对较低;说明价格在热度和销量中有一定影响,也反映出人们较关注性价比问题。
各品牌价格分析
1 | # 各品牌价格 |
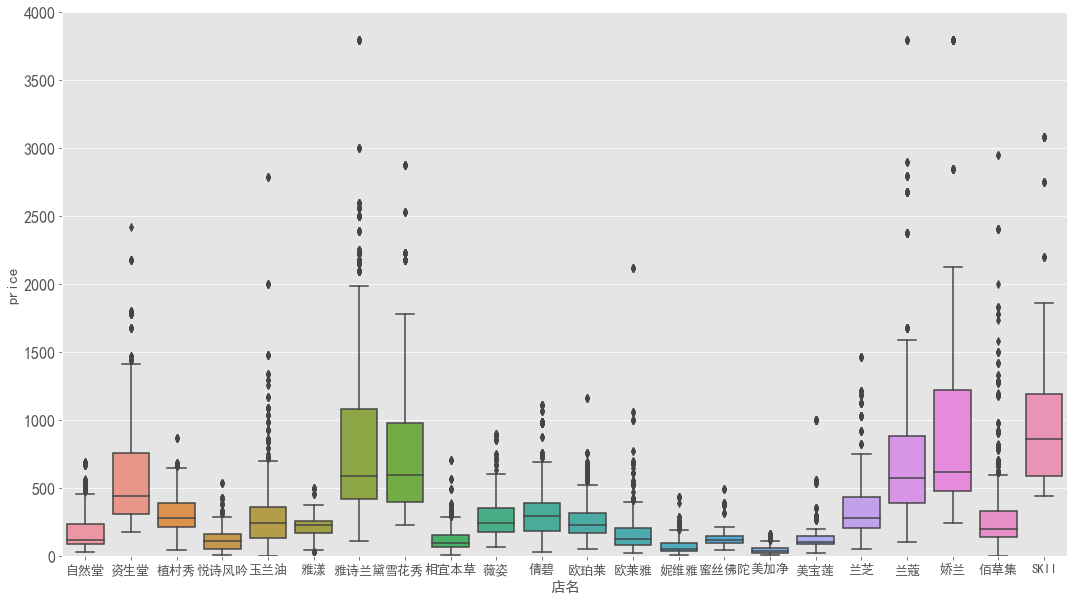
1 | # 各品牌的平均价格 |
店名
SKII 1011.727079
佰草集 289.823171
倩碧 346.092190
兰芝 356.615809
兰蔻 756.400778
妮维雅 73.789053
娇兰 1361.043588
悦诗风吟 121.245945
植村秀 311.786667
欧珀莱 276.218543
欧莱雅 167.282698
玉兰油 329.657294
相宜本草 122.958446
美加净 44.694619
美宝莲 148.757576
自然堂 180.130213
薇姿 281.085791
蜜丝佛陀 142.118894
资生堂 577.438490
雅漾 212.618401
雅诗兰黛 872.470718
雪花秀 901.082873
Name: price, dtype: float64
1 | fig = plt.figure(figsize=(19,10)) |
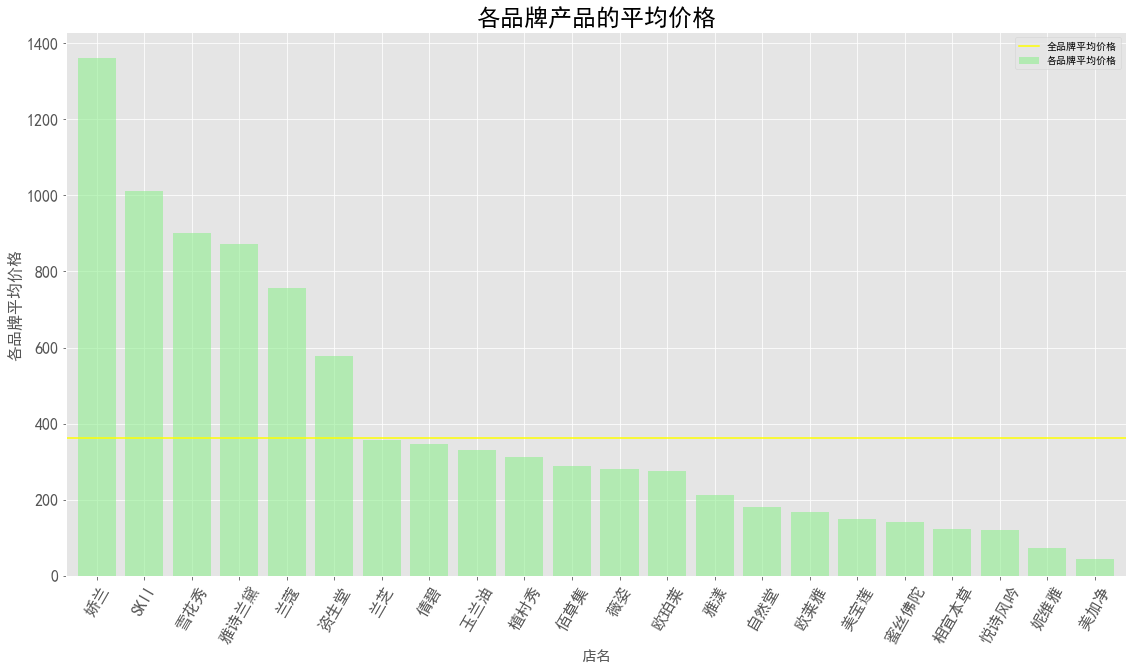
图表解析:
- 娇兰、SKII、雪花秀、雅诗兰黛、兰蔻、资生堂均是国际大牌,产品平均价格都在500以上,属于一线大牌;
- 兰芝、倩碧、玉兰油、植村秀、佰草集、薇姿、雅漾的平均价格在300~400之间,其中佰草集是最贵的国货品牌;
- 美加净作为国货品牌,平均价格最低,性价比高,而妮维雅平均价格第二低;
- 全品牌的平均价格低于400元,而除了前六个国际大牌外的其他品牌的平均价格都低于全品牌的平均价格
平均销量&平均销售额
1 | # 各品牌平均销量和平均销售额 |
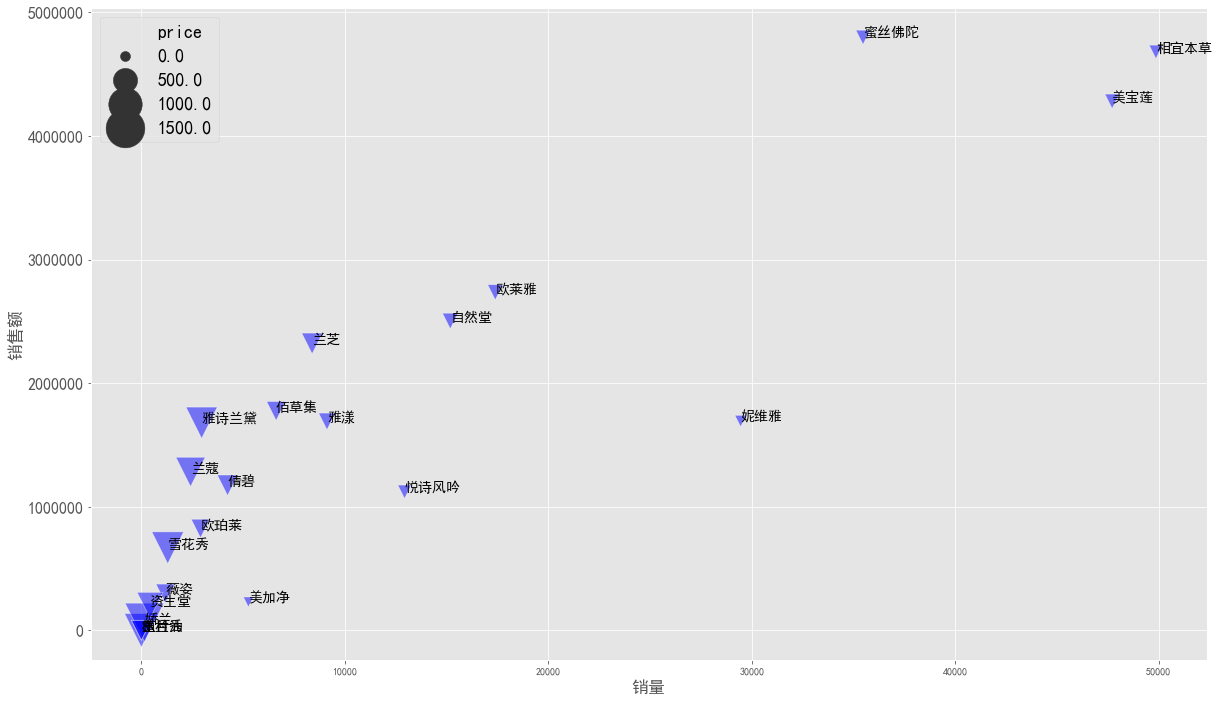
图表解析:
- 销售额越高越靠图像上方,销量越高越靠图像右方,图形越大代表平均价格越高
- 销量与销售额呈正相关
- 相宜本草、美宝莲、蜜丝佛陀销量与销售额在所有品牌中位列前三,而且平均价格较低
男性护肤品销量分析
1 | # 男性护肤品销量情况 |
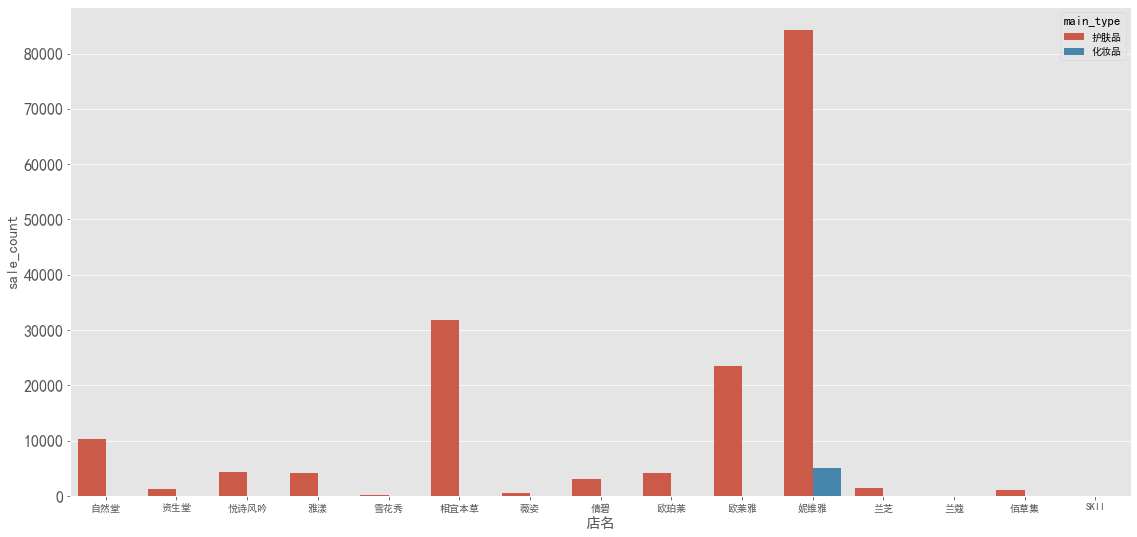
图表分析:男用大多购买的是护肤品
1 | f,[ax1,ax2] = plt.subplots(1,2,figsize=(19,9)) |
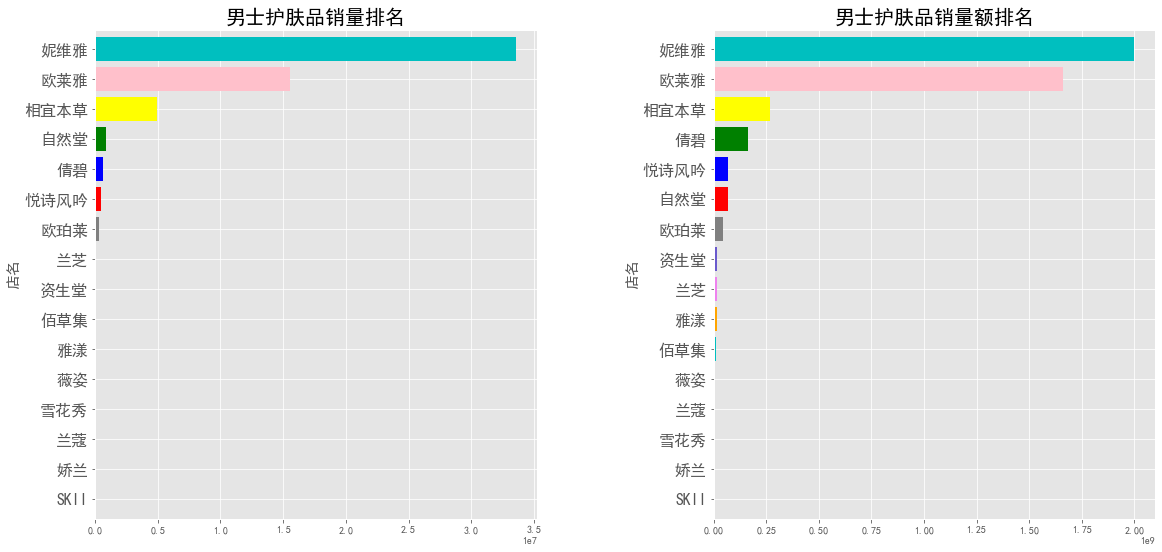
图表分析:
- 妮维雅是男士护肤品中购买首选,销量遥遥领先
- 欧莱雅、相宜本草、倩碧分别位于男士护肤品销量的二三四位
购买时间与销量分析
1 | # 时间与销量分析 -- 购买高峰期 |
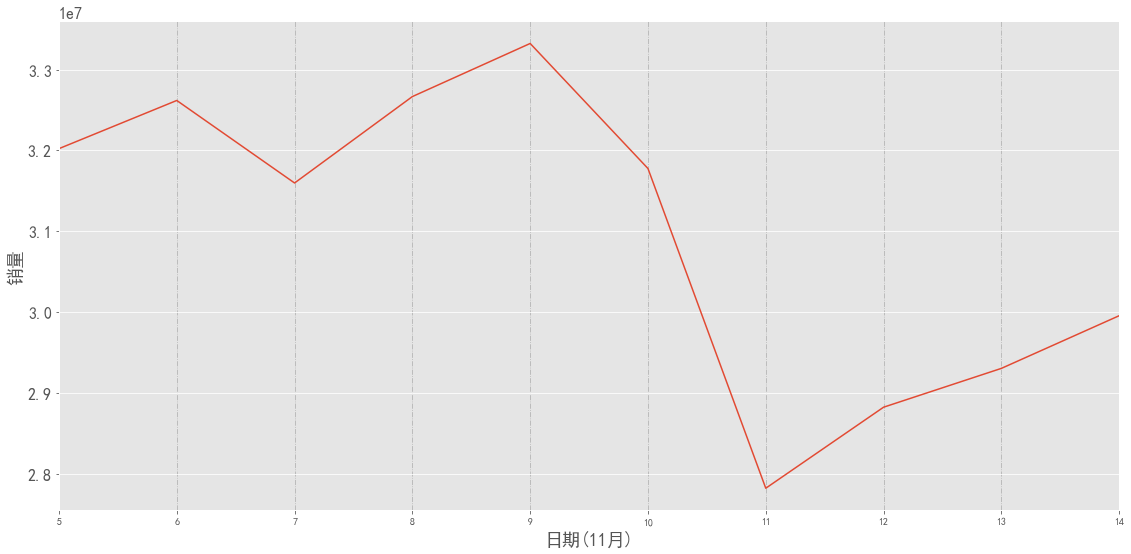
图表解析:
- 化妆品的购买高峰期在11号的前几天,猜测原因为双十一前商家为提前预热给出了较大优惠,导致了消费者的购买欲望加强
- 双十一当天销量最低
- 双十一后3天,销量较于11当天稳步上涨,可能是消费余热导致,也有可能是商家给出了新的优惠或是持续打折导致
总结
基于上方分析,做出以下总结整理:
- 美妆类别中护肤品销量远大于化妆品,而护肤品中又以清洁类、化妆水以及面霜等基础护肤类产品销量最高
- 男士使用的美妆产品集中在护肤品类别,在众多品牌中妮维雅是最受男士喜爱的品牌
- 价格和热度对销量有极大关联,平价的基础产品是大多数消费者的首选,也说明了消费者对性价比高的产品的热衷
- 可能是商家在双十一的提前预热,亦或是给出了巨大的优惠和为了避免11当天的消费高峰,不少消费者选择了提前消费,导致了销量高峰出现在双十一的前几天,而非11日当天
- 双十一后3天,消费者还留有购物余热,但销量远不如双十一之前
写在最后
以上为双十一天猫美妆产品销售数据分析以及可视化。有错误及不足之处,恳请指正,感谢阅读。