摘要
从常用的MySQL关键字到MySQL语句的书写,再到MySQL语句的执行,一步步深入学习MySQL~
MySQL常用的关键字
必选字段:SELECT、FROM
可选字段:DISTINCT、JOIN、ON、WHERE、GROUP BY、HAVING、ORDER BY、LIMIT
聚合函数:COUNT(计数)、SUM(求和)、max(最大值)、min(最小值)、avg(平均值)、group_concat(字符串连接)
#COUNT(1) & COUNT(COLUMN)区别
当数据集中不包含NULL值时,两者表现一致;当出现NULL值时,COUNT(COLUMN)不将NULL值所在行计入总数,相当于进行非NULL值计数。
#实例
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
USE cnt_exp;
CREATE TABLE stu(
id int,
name varchar(10),
classid int);
INSERT into stu values
(1,'A',1),(2,'B',1),(3,'C',2),(4,'D',2),(5,'A',1),(6,'F',1),(7,NULL,2);
SELECT * FROM stu;
+------+------+---------+
| id | name | classid |
+------+------+---------+
| 1 | A | 1 |
| 2 | B | 1 |
| 3 | C | 2 |
| 4 | D | 2 |
| 5 | A | 1 |
| 6 | F | 1 |
| 7 | NULL | 2 |
+------+------+---------+
SELECT COUNT(1),classid FROM stu GROUP BY classid;
+----------+---------+
| count(1) | classid |
+----------+---------+
| 4 | 1 |
| 3 | 2 |
+----------+---------+
SELECT COUNT(name),classid FROM stu GROUP BY classid;
+-------------+---------+
| count(name) | classid |
+-------------+---------+
| 4 | 1 |
| 2 | 2 |
+-------------+---------+
SELECT COUNT(DISTINCT name),classid FROM stu GROUP BY classid;
+----------------------+---------+
| COUNT(DISTINCT name) | classid |
+----------------------+---------+
| 3 | 1 |
| 2 | 2 |
+----------------------+---------+
MySQL书写顺序
常见的MySQL语句
SELECT -> DISTINCT -> FROM -> JOIN -> ON -> WHERE -> GROUP BY -> HAVING -> ORDER BY -> LIMIT
MySQL执行顺序
–查询组合字段
(8) SELECT (9) DISTINCT <select_list>
(1) FROM
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) WITH {CUBE|ROLLUP}
(7) HAVING<having_condition>
(10) ORDER BY <order_by_list>
(11) LIMIT <limit_number>
mysql关键词含义
- FROM:对FROM子句中的左表<left_table>和右表<right_table>执行笛卡尔乘积,产生虚拟表 VT1
- ON:对虚拟表VT1根据<join_condition>进行ON筛选,符合的行插入虚拟表VT2
- JOIN:如果指定了OUTER JOIN (如LEFT OUTER JOIN、RIGHT OUTER JOIN),那么保留表中未匹配的行作为外部行添加到虚拟表VT2中,产生虚拟表VT3。如果FROM子句中包含两个以上表,则对上一个连接生产的结果表VT3和下一个表进行重复执行(步骤1~步骤3),直到连接完所有的表
- WHERE:对虚拟表VT3根据<where_condition>进行WHERE过滤,符合的行插入虚拟表VT4
- GROUP BY:根据GROUP BY子句中的列,对虚拟表VT4中的数据进行分组操作,产生VT5
- CUBE|ROLLUP:对虚拟表VT5进行CUBE|ROLLUP操作,产生虚拟表VT6
- HAVING:对虚拟表VT6根据<having_condition>进行HAVING筛选,符合的行插入虚拟表VT7
- SELECT:根据SELECT选择指定的列,结果插入虚拟表VT8中
- DISTINCT:去除重复数据,结果插入虚拟表VT9
- ORDER BY:将虚拟表VT9按照<order_by_list>进行排序操作,产生虚拟表VT10
- LIMIT:根据<limit_number>取出指定行的数据,产生虚拟表VT11,并返回给查询用户
实例剖析
创建数据
1 | CREATE TABLE customers( |
情景模拟
-
题目:查询来自杭州且订单数少于2的客户,并且查询出他们的订单数量,查询结果按订单数从小到大排序
-
解答
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16SELECT customers.c_id,COUNT(order_id) AS total_orders
FROM customers
LEFT JOIN orders
ON customers.c_id = orders.c_id
WHERE city='HangZhou'
GROUP BY customers.c_id
HAVING COUNT(orders.order_id)<2
ORDER BY total_orders DESC;
+-------+--------------+
| c_id | total_orders |
+-------+--------------+
| TX | 1 |
| baidu | 0 |
+-------+--------------+
执行过程
(1) 执行FROM子句
即对FROM子句前后两张表进行笛卡尔乘积操作,也称作交叉连接,生成虚拟表VT1。如果FROM子句前表有a行数据,后表有b行数据,则虚拟表VT1中将包行a*b行数据。
FROM customers JOIN orders
虚拟表VT1
1 | SELECT * FROM customers JOIN orders; |
(2) 应用ON过滤
根据(1)中生成的虚拟表VT1,过滤条件为:
ON customers.c_id = orders.c_id
在产生虚拟表VT2时,会额外增加一个列来表示ON过滤条件的返回值,返回值有TRUE、FALSE、UNKNOWN。再取出比较值为TRUE的数据行,产生虚拟表VT2
虚拟表VT2
1 | SELECT * FROM customers JOIN orders ON customers.c_id = orders.c_id; |
(3) 添加外部行
这一步只有在连接类型为OUTER JOIN时才发生,即LEFT OUTER JOIN、RIGHT OUTER JOIN、FULL OUTER JOIN。LEFT OUTER JOIN把左表记为保留表(即保留左表全部数据行),RIGHT OUTER JOIN把右表记为保留表,而FULL OUTER JION把左右表都记为保留表。具体可以参考下面图SQL_JOINS(图片来源网络,侵删)
图SQL_JOINS
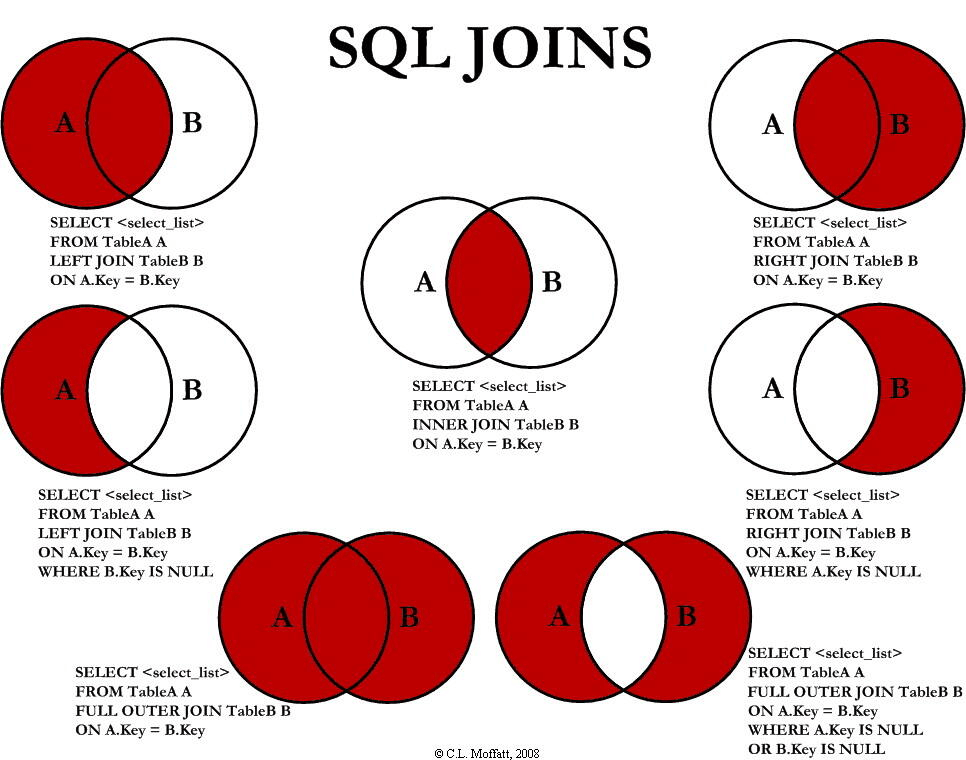
添加外部行执行内容就是在虚拟表VT2的基础上添加保留表中被过滤条件过滤掉的数据,非保留表中的数据则被赋予NULL值,最后生成虚拟表VT3
虚拟表VT3
1 | SELECT * FROM customers LEFT JOIN orders on customers.c_id = orders.c_id; |
(4) 应用WHERE过滤
根据(3)生成的虚拟表VT3进行WHERE条件的过滤,符合<where_condition>的数据行输出生成虚拟表VT4。过滤条件为:
WHERE customers.city = ‘HangZhou’
虚拟表VT4
1 |
|
tips:在应用WHERE过滤时,需要严格注意之前未使用过的过滤项,例如以下两种情况
- 未进行数据分组,不能在当前的WHERE过滤中使用<where_condition> = MIN(col) 这种聚合函数式的过滤
- 如果别名出现在SELECT中,则在当前WHERE过滤中不能使用该别名;原因是语句的执行顺序
(5) 分组
根据指定的<group_by_list>对(4)中生成的虚拟表进行分组,并生成虚拟表VT5;分组条件为:
GROUP BY customers.c_id;
虚拟表VT5
1 | SELECT * FROM customers LEFT JOIN orders on customers.c_id = orders.c_id |
(6) 并未应用ROLLUP或CUBE,跳过
(7) 应用HAVING过滤
根据(5)生成的虚拟表VT5进行HAVING条件过滤,符合<having_condition>的数据行输出生成虚拟表VT6,过滤条件为:
HAVING count(orders.order_id < 2)
虚拟表VT6
1 | SELECT * FROM customers LEFT JOIN orders on customers.c_id = orders.c_id |
(8) 筛选 - SELECT列表
将SELECT子句中的列从(7)生成的虚拟表VT6中筛选出来,生成虚拟表VT7,筛选条件为:
SELECT customers.c_id,COUNT(order_id) AS total_orders
虚拟表VT7
1 | SELECT customers.c_id,COUNT(order_id) AS total_orders |
(9) 去重 - DISTINCT ,本实例未应用,跳过
(10) 排序 - ORDER BY
根据指定的<order_by_list>对(8)中生成的虚拟表VT7进行排列顺序,返回新的虚拟表VT8,排序条件为:
ORDER BY total_orders
虚拟表VT8
1 | SELECT customers.c_id,COUNT(order_id) AS total_orders |
(11) 选取数据 - LIMIT
tips:一般来说LIMIT和ORDER BY一起使用,因为没有ORDER BY的返回结果一般都是无序的
本次实例没有应用,跳过~
总结
以上是在学习MySQL的书写以及执行顺序记录的学习笔记,并通过实例进行各个执行步骤的拆解,可以更详细的了解一条MySQL语句的执行顺序以及每个步骤产生的结果。以上学习资源均来自网络,如有侵权,告知删除,感谢阅读~
参考文章: