摘要
项目名称 :人力资源分析 - 离职原因
数据来源 :数据来源于Kaggle中的人力资源分析项目
字段说明 :
left:是否离职
satisfaction_level:满意度
last_evaluation:绩效评估
number_project:完成项目数
average_montly_hours:平均每月工作时间
time_spend_company:为公司服务的年限
work_accident:是否有工作事故
promotion:过去5年是否有升职
department:部门
salary:薪资水平
项目目的 :通过已知的员工离职与否情况,探究哪些因素对员工的离职产生了较大的影响
环境解释 :基于jupyter notebook,可视化工具包:seaborn、matplotlib
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as plt%matplotlib inline import warningswarnings.filterwarnings('ignore' ) import osos.chdir(r'/Users/nanb/Documents/数据存放' ) sns.set_style('darkgrid' ) sns.set_context('paper' )
1 2 3 4 5 6 7 data = pd.read_csv('HR_comma_sep.csv' ,sep = ',' ) data.rename(columns={'promotion_last_5years' :'promotion' , 'sales' :'department' },inplace=True )
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14999 entries, 0 to 14998
Data columns (total 10 columns):
satisfaction_level 14999 non-null float64
last_evaluation 14999 non-null float64
number_project 14999 non-null int64
average_montly_hours 14999 non-null int64
time_spend_company 14999 non-null int64
Work_accident 14999 non-null int64
left 14999 non-null int64
promotion 14999 non-null int64
department 14999 non-null object
salary 14999 non-null object
dtypes: float64(2), int64(6), object(2)
memory usage: 1.1+ MB
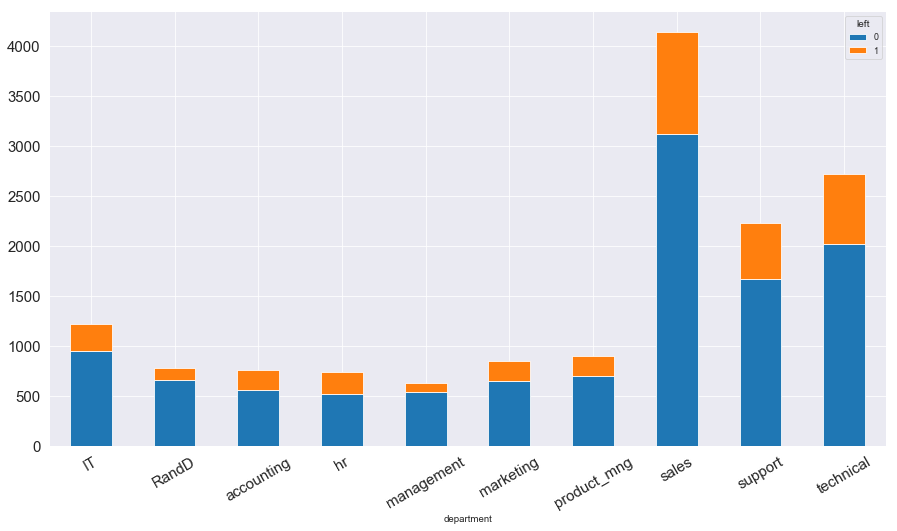
1 2 3 4 5 6 7 8 depart_left_table = pd.crosstab(index = data['department' ],columns = data['left' ]) depart_left_table.plot(kind = 'bar' ,figsize = (15 ,8 ), stacked = True , fontsize = 15 ) plt.xticks(rotation = 30 )
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]), <a list of 10 Text xticklabel objects>)
部门名称:sales(销售)、technical(技术)、support(支持)、IT、product_mng(产品经理)、marketing(市场营销)、RandD(研发)、accounting(会计)、hr、management(管理)
图表解析 :除sales、technical、support离职率较高之外,其余部门的离职率大致相似;其中管理岗位离职率较低,可能是管理者处于公司地位较高,这类型不倾向于离开
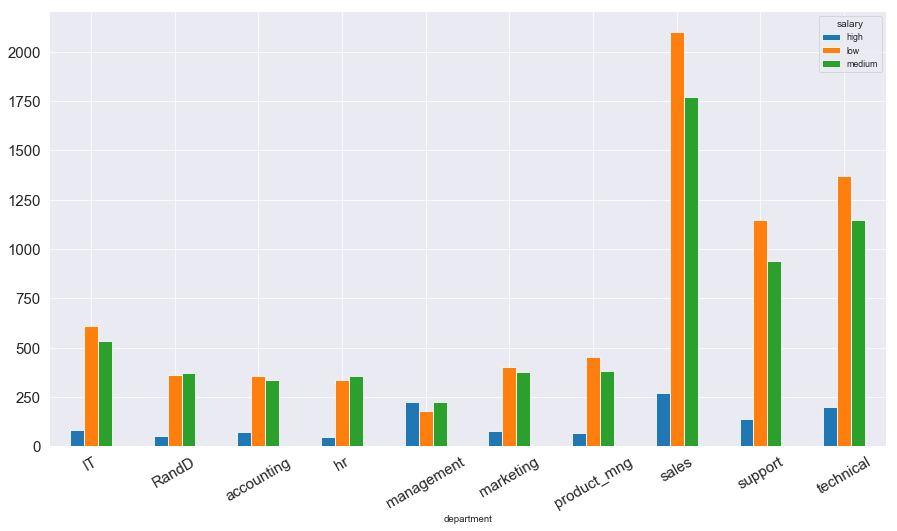
1 2 3 4 5 6 depart_salary = pd.crosstab(index = data['department' ],columns = data['salary' ]) depart_salary.plot(kind = 'bar' ,figsize = (15 ,8 ), fontsize = 15 ) plt.xticks(rotation = 30 )
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]), <a list of 10 Text xticklabel objects>)
图表解析 :销售sales的工资基本处于低中水平,可能是导致离职率较高的因素;而管理层的薪资基本都在中高水平,离职率也最低
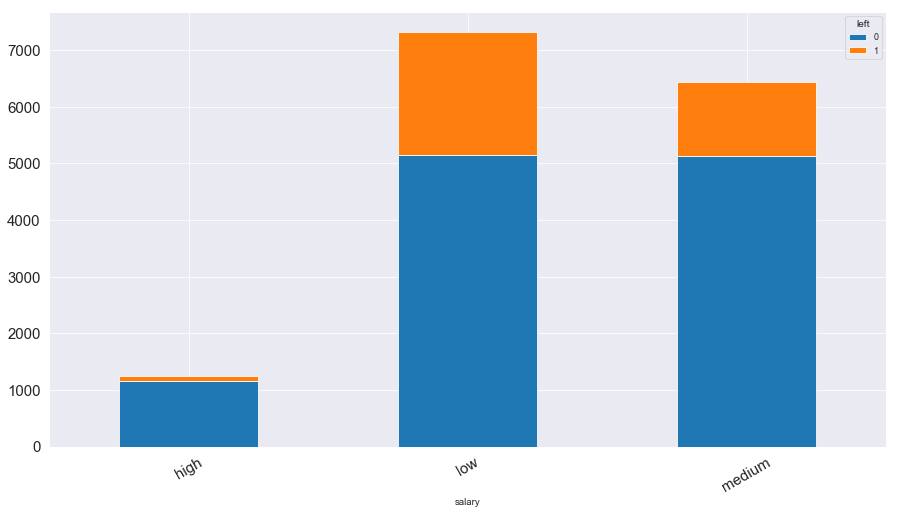
1 2 3 4 5 6 salary_left = pd.crosstab(index = data['salary' ],columns = data['left' ]) salary_left.plot(kind = 'bar' ,figsize = (15 ,8 ),stacked = True , fontsize = 15 ) plt.xticks(rotation = 30 )
(array([0, 1, 2]), <a list of 3 Text xticklabel objects>)
图表解析 :很直观的看出,离职的员工大多数薪资都在低到中等的水平,而很少有高薪资的员工离开公司
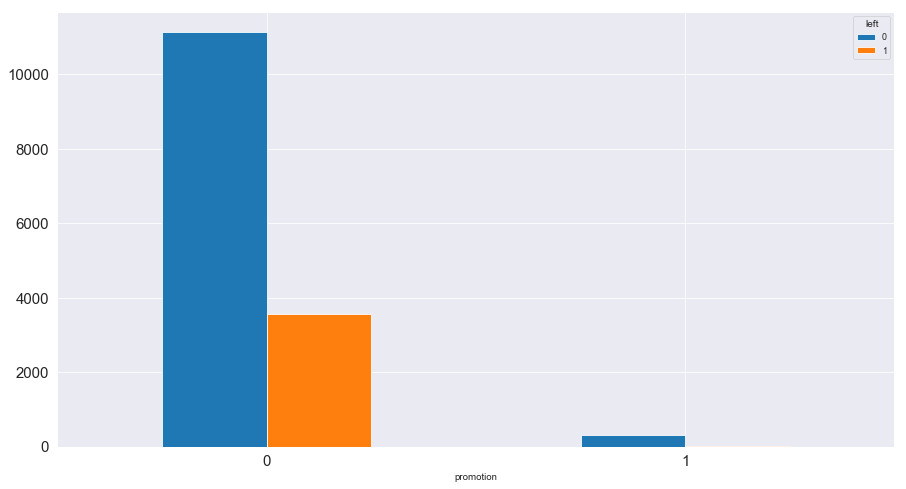
1 2 3 4 5 6 7 promotion_left = pd.crosstab(index = data['promotion' ],columns = data['left' ]) promotion_left.plot(kind = 'bar' ,figsize = (15 ,8 ), fontsize = 15 ) plt.xticks(rotation = 360 )
(array([0, 1]), <a list of 2 Text xticklabel objects>)
图表解析 :明显得知,离职员工中几乎都没有得到过升职,而得到升职的员工基本都没有离开
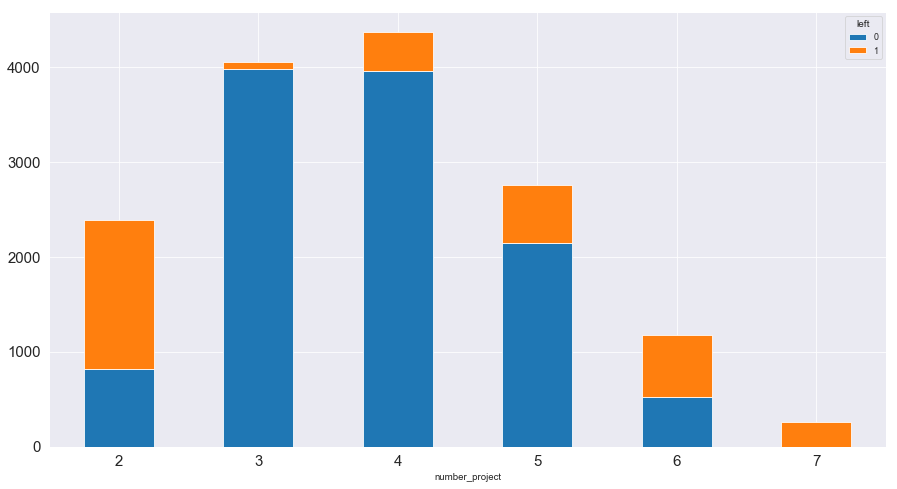
1 2 3 4 5 6 7 8 number_prj_left = pd.crosstab(index = data['number_project' ], columns = data['left' ]) number_prj_left.plot(kind = 'bar' ,figsize = (15 ,8 ),stacked = True , fontsize = 15 ) plt.xticks(rotation = 360 )
(array([0, 1, 2, 3, 4, 5]), <a list of 6 Text xticklabel objects>)
图表解析 :超过一半的员工只有2个项目就离开了公司;同样有从4-7个项目统计的员工离职,并且随着项目的增多,员工离职率逐渐增高;3个项目的员工离职率最低
猜测:
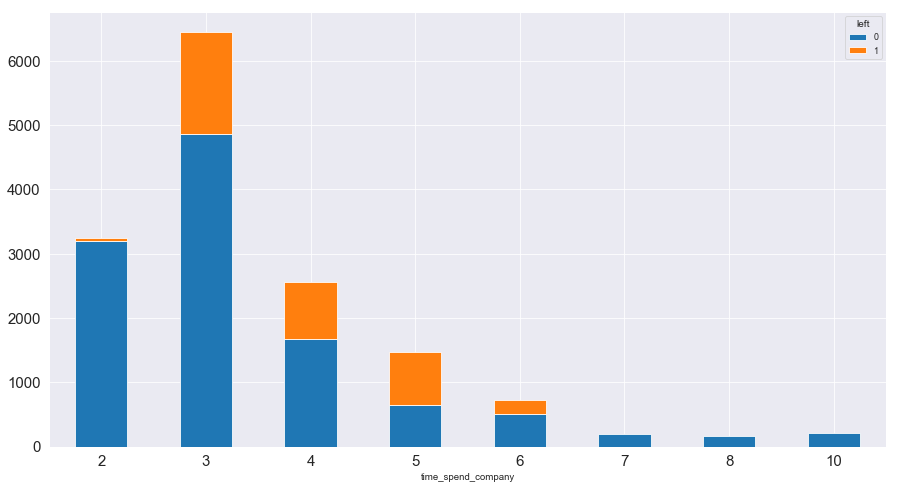
1 2 3 4 5 6 time_spend_compy_left = pd.crosstab(index = data['time_spend_company' ],columns = data['left' ]) time_spend_compy_left.plot(kind = 'bar' ,figsize = (15 ,8 ), stacked = True ,fontsize = 15 ) plt.xticks(rotation = 360 )
(array([0, 1, 2, 3, 4, 5, 6, 7]), <a list of 8 Text xticklabel objects>)
图表解析 :离职员工在离职前大多数在公司已经工作3-5年;在公司工作7年及以上几乎没有人离职;在公司工作2年的员工基本上也不会选择离职
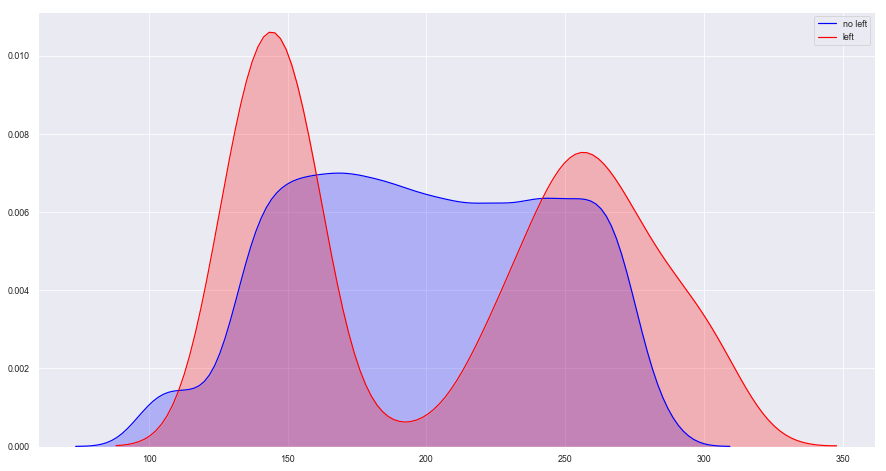
1 2 3 4 5 6 7 plt.figure(figsize = (15 ,8 )) sns.kdeplot(data.loc[(data['left' ] == 0 ),'average_montly_hours' ],color = 'b' ,shade = True ,label = 'no left' ) sns.kdeplot(data.loc[(data['left' ] == 1 ),'average_montly_hours' ],color = 'r' ,shade = True ,label = 'left' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a23732d68>
图表解析 :就离职部分员工来说,很明显的双峰分布,说明员工每月平均工作时长低于150小时和工作时长高与250小时的员工离职率最高。
简言之,一般离开公司的员工要么工作时间少,要么就是过度工作
1 2 3 4 5 6 7 plt.figure(figsize = (15 ,8 )) sns.kdeplot(data.loc[(data['left' ] == 0 ),'last_evaluation' ],color = 'b' ,shade = True ,label = 'no left' ) sns.kdeplot(data.loc[(data['left' ] == 1 ),'last_evaluation' ],color = 'r' ,shade = True ,label = 'left' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a2393ecf8>
图表解析 :也是一个双峰分布:表现糟糕的和表现优秀的员工出现了离职的两个峰值。有可能是绩效评估出色的员工,公司没有相应的转换到升职和加薪上,导致了表现优秀的员工离职率变高;而绩效评估在0.6~0.8之间员工有较高的留存率
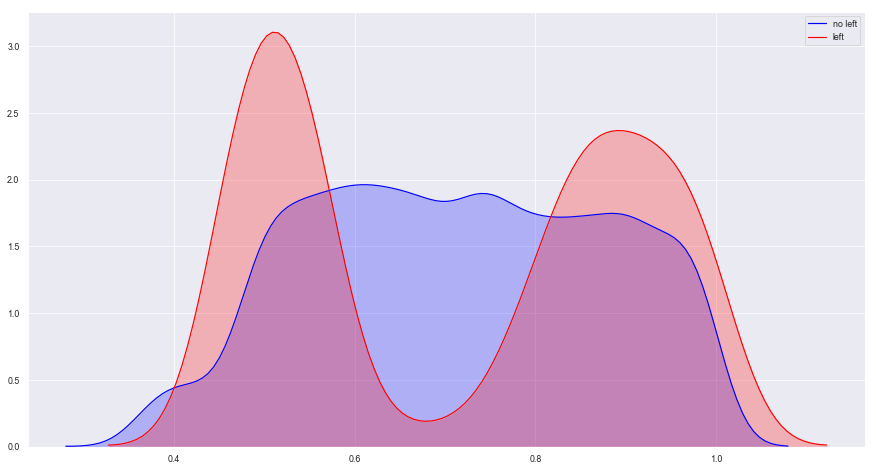
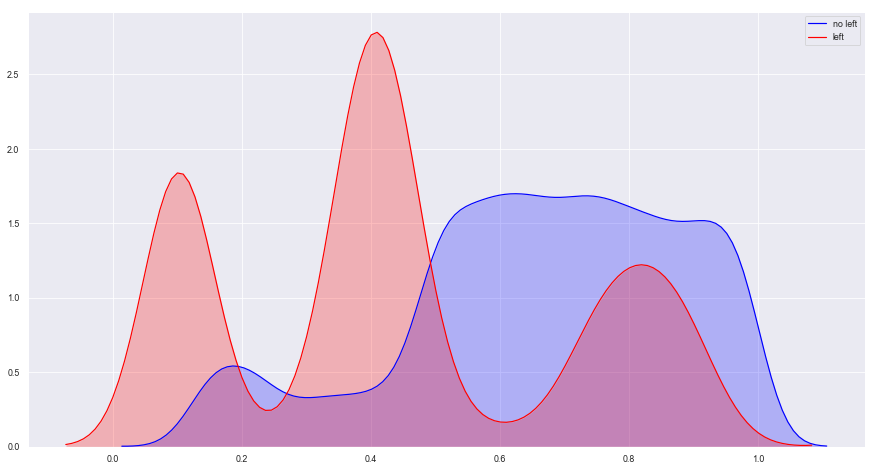
1 2 3 4 5 6 plt.figure(figsize = (15 ,8 )) sns.kdeplot(data.loc[(data['left' ] == 0 ),'satisfaction_level' ],color = 'b' ,shade = True ,label = 'no left' ) sns.kdeplot(data.loc[(data['left' ] == 1 ),'satisfaction_level' ],color = 'r' ,shade = True ,label = 'left' )
<matplotlib.axes._subplots.AxesSubplot at 0x1a2393e0b8>
图表解析 :
图中出现了三个峰值:满意度低于0.1的员工基本离职;满意度在0.3-0.5之间离职的员工又达到一个峰值;而在满意度为0.8左右时,离职情况又出现了一个峰值。
猜测:满意度较高的员工出现离职的情况,有可能是有更好的工作机会,而不一定是对公司不满所引发的离开
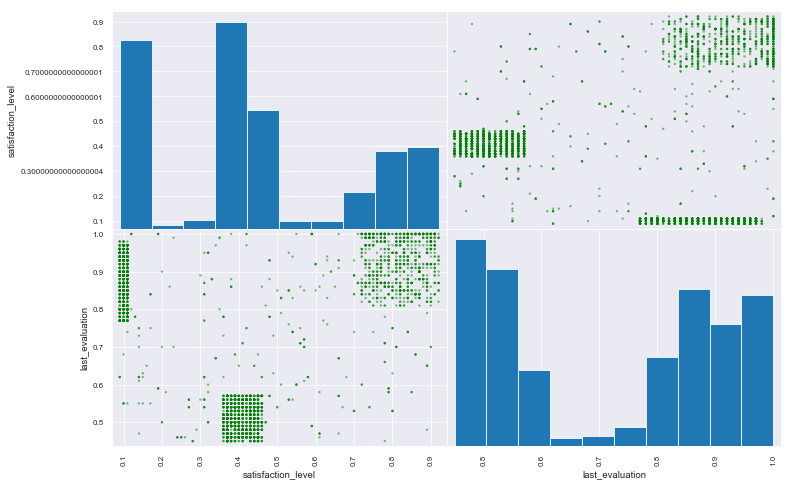
1 2 3 4 5 df = data[data['left' ] == 1 ] pd.plotting.scatter_matrix(df[['satisfaction_level' ,'last_evaluation' ]], color = 'g' ,figsize = (12 ,8 ))
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x1a23d02b00>,
<matplotlib.axes._subplots.AxesSubplot object at 0x1a21b92cc0>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x1a23d6c668>,
<matplotlib.axes._subplots.AxesSubplot object at 0x1a23f25fd0>]],
dtype=object)
从绩效评估和满意度的散射矩阵中,大致分为三个不同的集群
1、集群1:满意度低于0.2,绩效评估大于0.75,这很直观的表明离开公司的员工在工作上受到高度评价,但是对自己的工作并不满意;所以该集群可能代表着’过度劳累’部分的员工
2、集群2:满意度在0.35~0.45之间,绩效评估在0.58以下;这部分员工在工作上受到不太好的评价,可能代表着员工本身表现不大好,而且员工对公司的满意度也不好
3、集群3:满意度在0.7~1之间,绩效评估大于0.8;这部分员工不仅在工作上受到高度评价,而且对公司的满意度也高;假如这个类别的员工离职,可能是有了更好的工作机会,包括更高的薪资、更好的发展机会或者更大的晋升空间等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from sklearn.preprocessing import MinMaxScaler,StandardScalerfrom sklearn.preprocessing import LabelEncoder,OneHotEncoderfrom sklearn.preprocessing import Normalizerfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysisfrom sklearn.decomposition import PCA
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ''' sl:satisfaction_level --- False:MinMaxScaler;True:StandardScaler le:last_evaluation --- False:MinMaxScaler;True:StandardScaler npr:number_project --- False:MinMaxScaler;True:StandardScaler amh:average_montly_hours --- False:MinMaxScaler;True:StandardScaler tsc:time_spend_company --- False:MinMaxScaler;True:StandardScaler wa:work_accident --- False:MinMaxScaler;True:StandardScaler pl5:promotion --- False:MinMaxScaler;True:StandardScaler dp:department --- False:LabelEncoding;True:OneHotEncoding slr:salary --- False:LabelEncoding;True:OneHotEncoding '''
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 def hr_preprocessing (sl=False ,le=False ,npr=False ,amh=False ,tsc=False ,wa=False ,pl5=False ,dp=False ,slr=False ,lower_d=False ,ld_n=1 ): global data label = df['left' ] data = data.drop('left' ,axis = 1 ) scaler_lst = [sl,le,npr,amh,tsc,wa,pl5] column_lst = ['satisfaction_level' ,'last_evaluation' ,\ 'number_project' ,'average_montly_hours' ,\ 'time_spend_company' ,'Work_accident' ,'promotion' ] for i in range (len (scaler_lst)): if not scaler_lst[i]: data[column_lst[i]] = \ MinMaxScaler().fit_transform(data[column_lst[i]].values.reshape(-1 ,1 )).reshape(1 ,-1 )[0 ] else : data[column_lst[i]] = \ StandardScaler().fit_transform(data[column_lst[i]].values.reshape(-1 ,1 )).reshape(1 ,-1 )[0 ] scaler_lst = [slr,dp] column_lst = ['salary' ,'department' ] for i in range (len (scaler_lst)): if not scaler_lst[i]: if column_lst[i] == 'salary' : data[column_lst[i]] = [map_salary(s) for s in data['salary' ].values] else : data[column_lst[i]] = LabelEncoder().fit_transform(data[column_lst[i]]) data[column_lst[i]] = MinMaxScaler().fit_transform(data[column_lst[i]].values.reshape(-1 ,1 )).reshape(1 ,-1 )[0 ] else : data = pd.get_dummies(data,columns=[column_lst[i]]) if lower_d: return PCA(n_components=ld_n).fit_transform(data.values),label return data,labels d = dict ([('low' ,0 ),('medium' ,1 ),('high' ,2 )]) def map_salary (s ): return d.get(s,0 ) def main (): print (hr_preprocessing(lower_d=True ,ld_n=3 )) main()
(array([[-0.14989291, -0.4220161 , -0.42173539],
[-0.14643287, 0.41677176, 0.1984778 ],
[-0.26709532, 0.68671233, 0.18811401],
...,
[-0.14803561, -0.43441955, -0.503113 ],
[-0.29885501, 0.76297807, -0.24200472],
[-0.15087015, -0.41003776, -0.49717793]]), 0 1
1 1
2 1
3 1
..
14996 1
14997 1
14998 1
Name: left, Length: 3571, dtype: int64)
未完待续~
以上是基于HR数据进行的员工离职原因案例的一部分分析,剩余预测模型的构建,也就是算法部分,目前对算法的了解尚浅,能力不足以处理,待学习后进行补充。对以上分析有疑义,欢迎指正,感谢阅读~